






One of our goals with Pipeline is to support Java and Java Enterprise Edition deployments, allowing developers to iterate fast while building and deploying safe, and also pushing code to production. In order to do that, we place a lot of importance on different aspects of a Java/JEE application’s lifecycle - we allow engineers:
- To continuously integrate and deploy their Java apps to Kubernetes
- To deploy Java Enterprise Edition applications to Kubernetes
- Once the Java containers are deployed to K8s, to avoid OOMKills
- To correctly size Java containers
- And, once deployments are done and sized, to monitor them without any code modification
Enter Infinispan - a distributed cache and data grid.
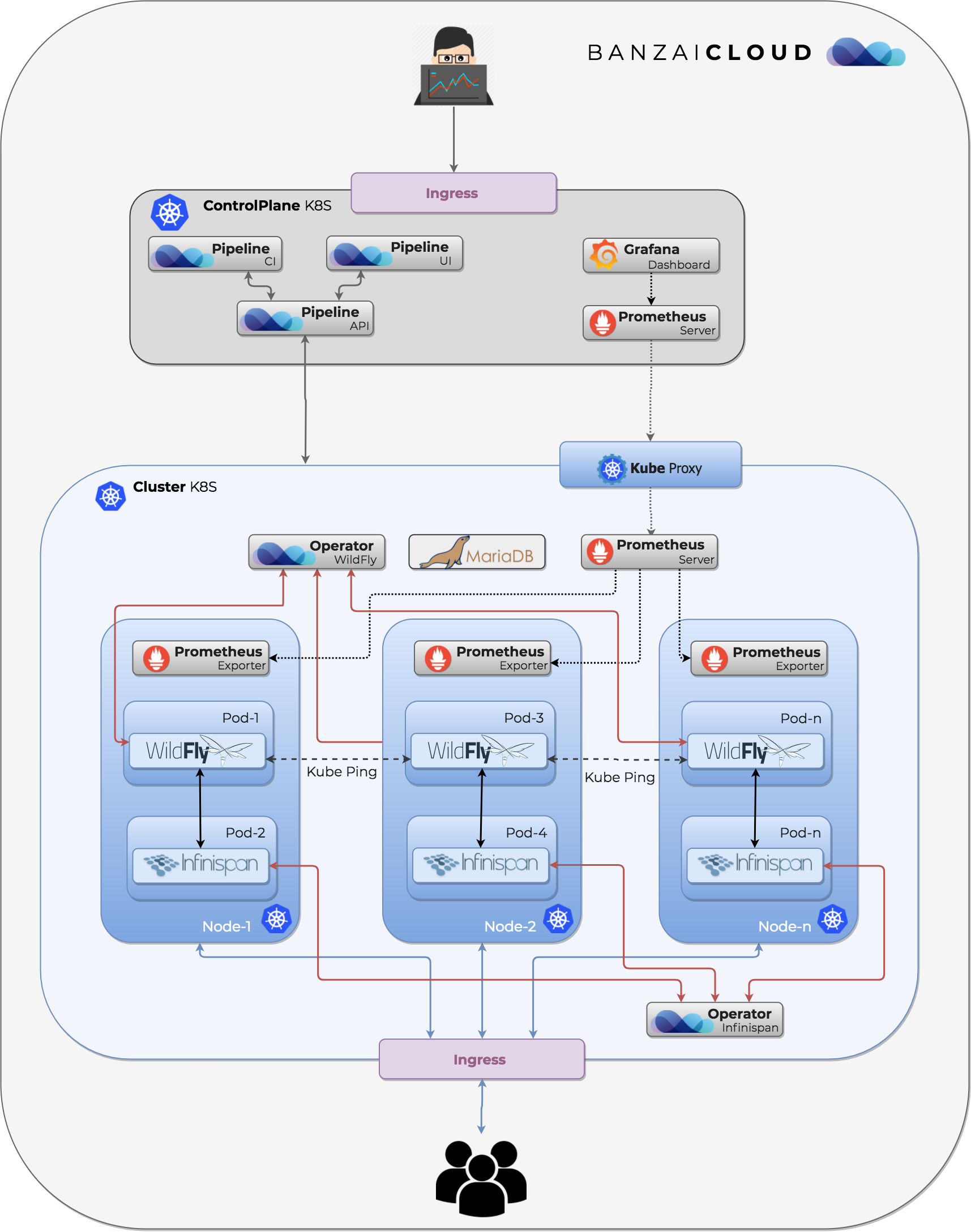
The Infinispan Operator 🔗︎
A month ago the new Kubernetes operators SDK was released, and it’s been easier to put human operational knowledge into the code ever since. We embraced that technology from a very early stage, have even been a Red Hat partner working on the SDK. As a result we have open sourced a few operators for popular frameworks:
We are also working on an Infinispan Operator to run Infinispan clusters on Kubernetes, all built on the new operator SDK. One of the main benefits of this Operator is that, without deep Kubernetes, Helm and Infinispan operational knowledge, you can get a fully HA Infinispan cluster up and running on your Kubernetes cluster.
Nodes are automatically joined together with JGroups configured to use KUBE_PING protocol, which finds each Pod running an Infinispan server based on labels and namespaces. By default, the operator deploys a standalone Full HA configuration to Kubernetes.
Kubernetes discovery protocol for JGroups: In regular host based deployments, Infinispan uses JGroups to find each node. When deployed to Kubernetes the KUBE_PING discovery protocol for JGroups clusters is used instead. This discovery protocol is the result of Kubernetes asking for a list of the IP addresses of all cluster nodes, combined with bind_port/port_range; the protocol then sends a discovery request to all instances and waits for their responses. When a discovery is started,
KUBE_PINGasks Kubernetes for a list of the IP addresses of all the pods it launched, matching the given namespace and labels.
Once the operator deploys a cluster, the Infinispan REST and Management endpoints are exposed as Kubernetes Services and the Infinispan deployment is continuously monitored by Kubernetes through built-in Infinispan health checks.
This operator is in WIP state and subject to (breaking) changes.
Usage 🔗︎
Prerequisites 🔗︎
- Install the Operator SDK first: https://github.com/operator-framework/operator-sdk#quick-start
Clone the repository 🔗︎
mkdir -p $GOPATH/src/github.com/banzaicloud
cd $GOPATH/src/github.com/banzaicloud
git clone git@github.com:banzaicloud/infinispan-operator.git
cd infinispan-operator
Get the operator Docker image 🔗︎
a. Build the image yourself 🔗︎
operator-sdk build banzaicloud/infinispan-operator
docker tag banzaicloud/infinispan-operator ${your-operator-image-tag}:latest
docker push ${your-operator-image-tag}:latest
b. Use the image from Docker Hub 🔗︎
# No additional steps needed
Install the Kubernetes resources 🔗︎
Finally, you need to deploy the operator, see the running pods and services.
kubectl apply -f deploy
kubectl get pods
kubectl get services
The Infinispan Custom Resource - deploy a cluster 🔗︎
With this YAML template you can easily install a three node Infinispan Cluster into your Kubernetes cluster:
apiVersion: "infinispan.banzaicloud.com/v1alpha1"
kind: "Infinispan"
metadata:
name: "infinispan-example"
spec:
size: 3
That’s it: you’ll have an infinispan cluster in minutes.







