One of the key features of the Pipeline platform is its ability to automatically provision, manage, and operate different application frameworks through what we call spotguides. Among the many spotguides we support on Kubernetes (Spark, Zeppelin, NodeJS, Golang, even custom frameworks - to name a few) Apache Kafka is among the most popular.
We are heavily invested in making it as easy and straightforward as possible to operate Apache Kafka automatically on Kubernetes, and we believe that our current Apache Kafka Spotguide does just that. We’re not stopping there, and we highly encourage you to read the roadmap section at the end of this blog.
**Some of our older posts about Apache Kafka on Kuberbetes:** Kafka on Kubernetes - using etcd Monitoring Apache Kafka with Prometheus Kafka on Kubernetes with Local Persistent Volumes Kafka on Kubernetes the easy way
Kafka on Kubernetes - the way it should be 🔗︎
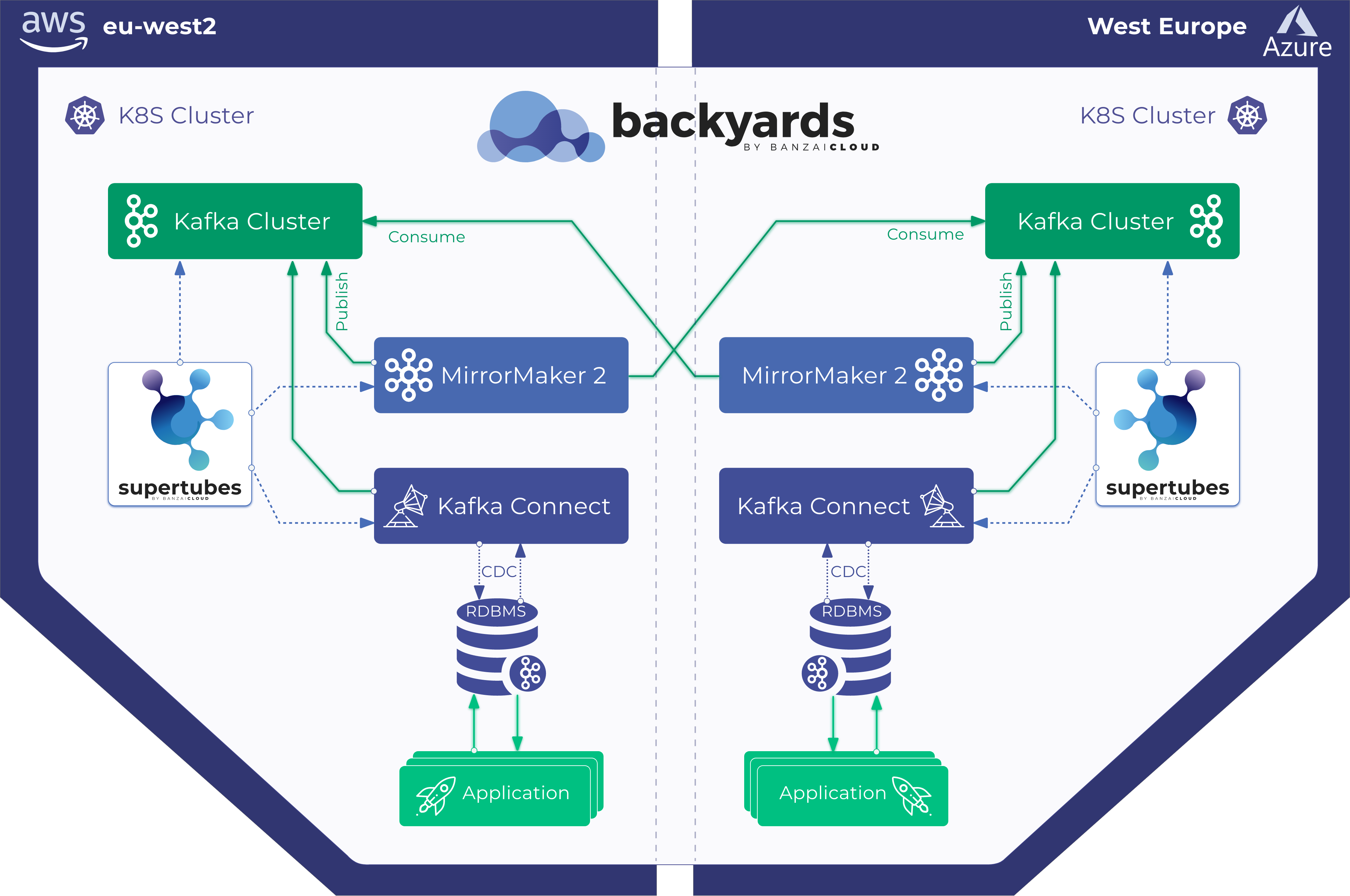
There are a few solutions out there for people that want to use Kafka on Kubernetes, but I’d argue that none of them provide an end-to-end method of creating, operating and deploying Kafka to Kubernetes without the use of specialized skillsets. Most of these solutions (if not all of them) require, as a prerequisite, a preexisting Kubernetes cluster, Helm or K8s deployment, knowledge of yaml, logging and monitoring systems that are pre-deployed and pre-configured, possibly a CI/CD system, marriage of Kafka and K8s security measures, and, ultimately, Kafka experience. These prerequisites don’t usually overlap, so our aim was to automate them and to fast track the Kafka on Kubernetes experience by:
- Automating the creation of Kubernetes clusters on six cloud providers as well as on-premise
- Deploying Kafka’s components and creating brokers and a Zookeeper cluster
- Pre-configure Prometheus to monitor all Kafka components with useful default Grafana dashboards
- Centralizing log collection (in object storage, Elastic, etc) using the fluentd/fluent-bit ecosystem
- Externalizing access to Kafka using a dynamically (re)configured Envoy proxy
- Reproducing environments using the built-in Pipeline CI/CD subsystem and storing state in Git
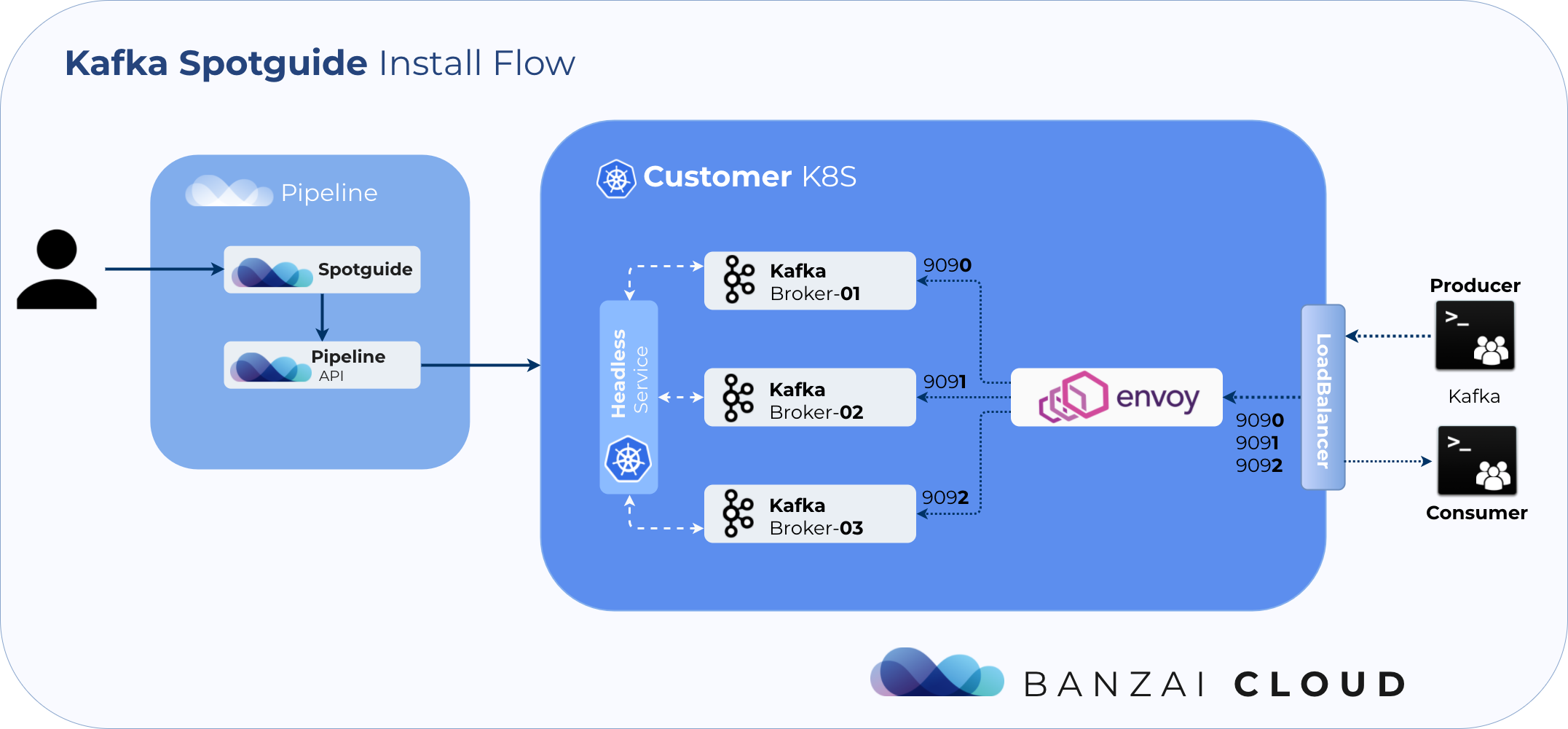
A competent Java/Kafka developer might lack any of the skills listed above - however, they can all be automated using Banzai Cloud’s Koperator for Kubernetes and our Kafka Spotguide. You can kickstart your Kafka experience in less than 5 minutes through the Pipeline UI.
An overview (including automation flow) follows:

Kafka in action 🔗︎
Once you’re logged in to the Pipeline platform, you can proceed directly to the Spotguides section (also, please check our documentation for details on how to add your cloud credentials).
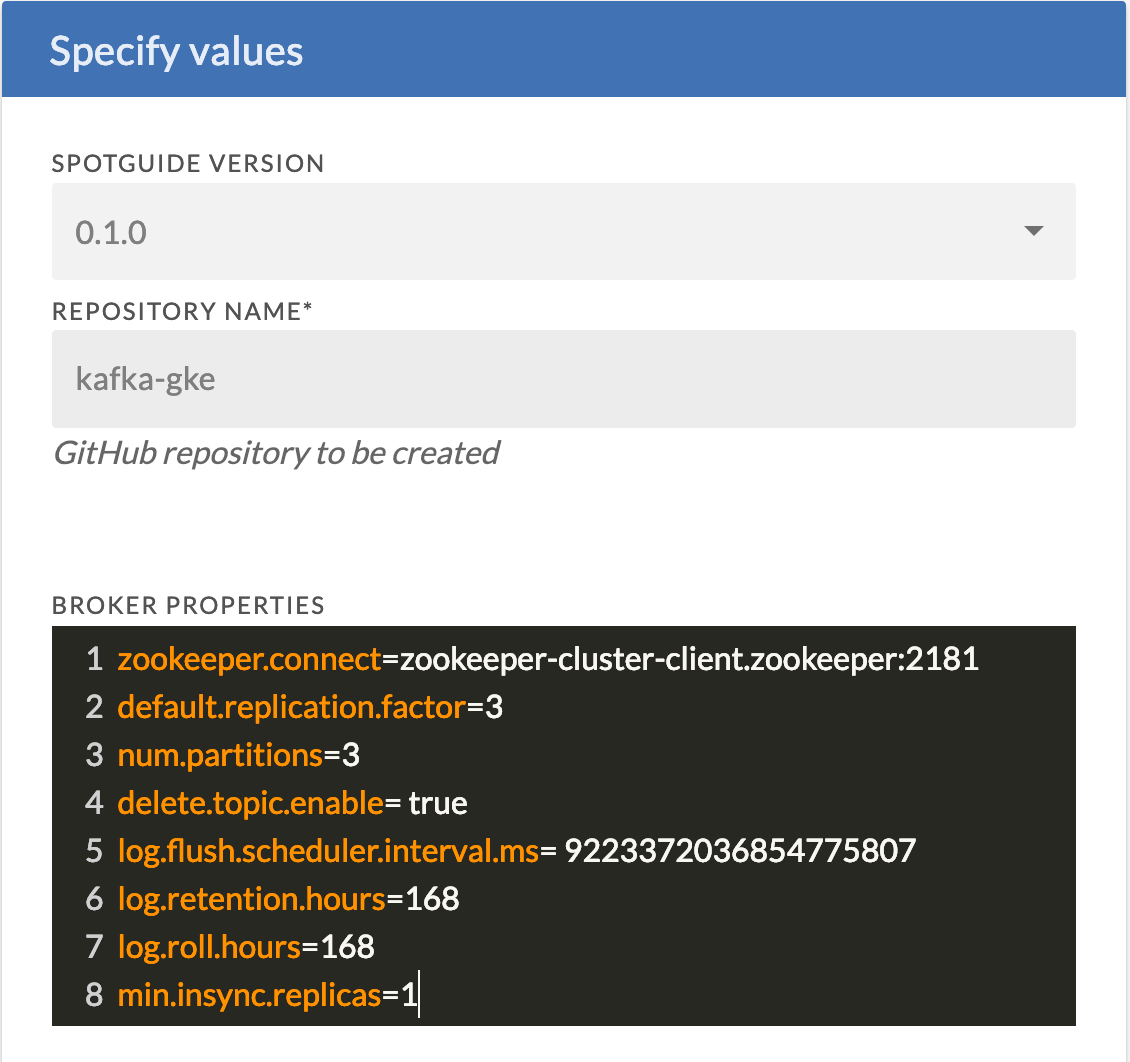
The first screen of the wizard/questionnaire will be a request for general information and for a handful of broker properties, which we will apply ourselves. Broker properties can contain anything covered in the original Kafka broker documentation. You can modify this snippet however you want, but it’s recommended that you take note of the following (we highly recommended you keep these as-is):
- zookeeper.connect: keep this or add your own pre-existing Zookeeper cluster endpoint
- broker.id: this is populated by the Spotguide based on the statefulset’s generated pod number
- advertised.listeners: this is populated by the Spotguide and cannot be changed in this release (we’ll add the option to later)
- listeners: this is also populated by the Spotguide and cannot be changed in this release (option to be added later)
- log.dirs: this is likewise populated by the Spotguide and cannot be changed in this release (option to later)

Once you pass these generic configs, you will reach the Kubernetes cluster create option. Once passed, the cluster is created, and Kafka and all its components are deployed and made ready to use (they’re monitored, their logs collected, etc).
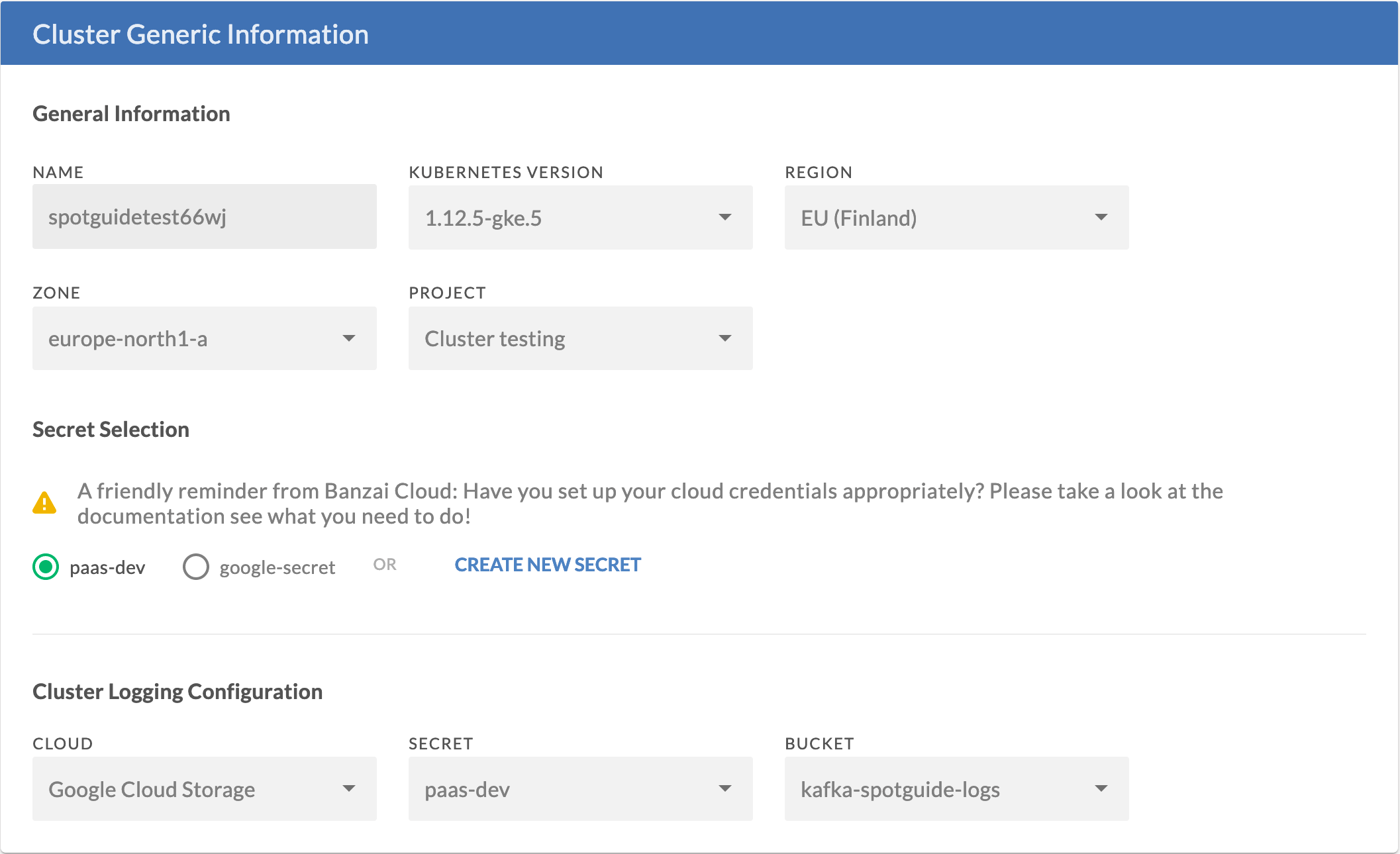
Now your Kafka cluster is ready!
Lets try it out by producing and consuming some messages. For practicality’s sake, these tests will be conducted using the well known Kafka tool, kafkacat.
- To produce messages:
kafkacat -P -b <bootstrap-server:port> -t test_topic - To consume those messages:
kafkacat -C -<bootstrap-server:port> -t test_topic
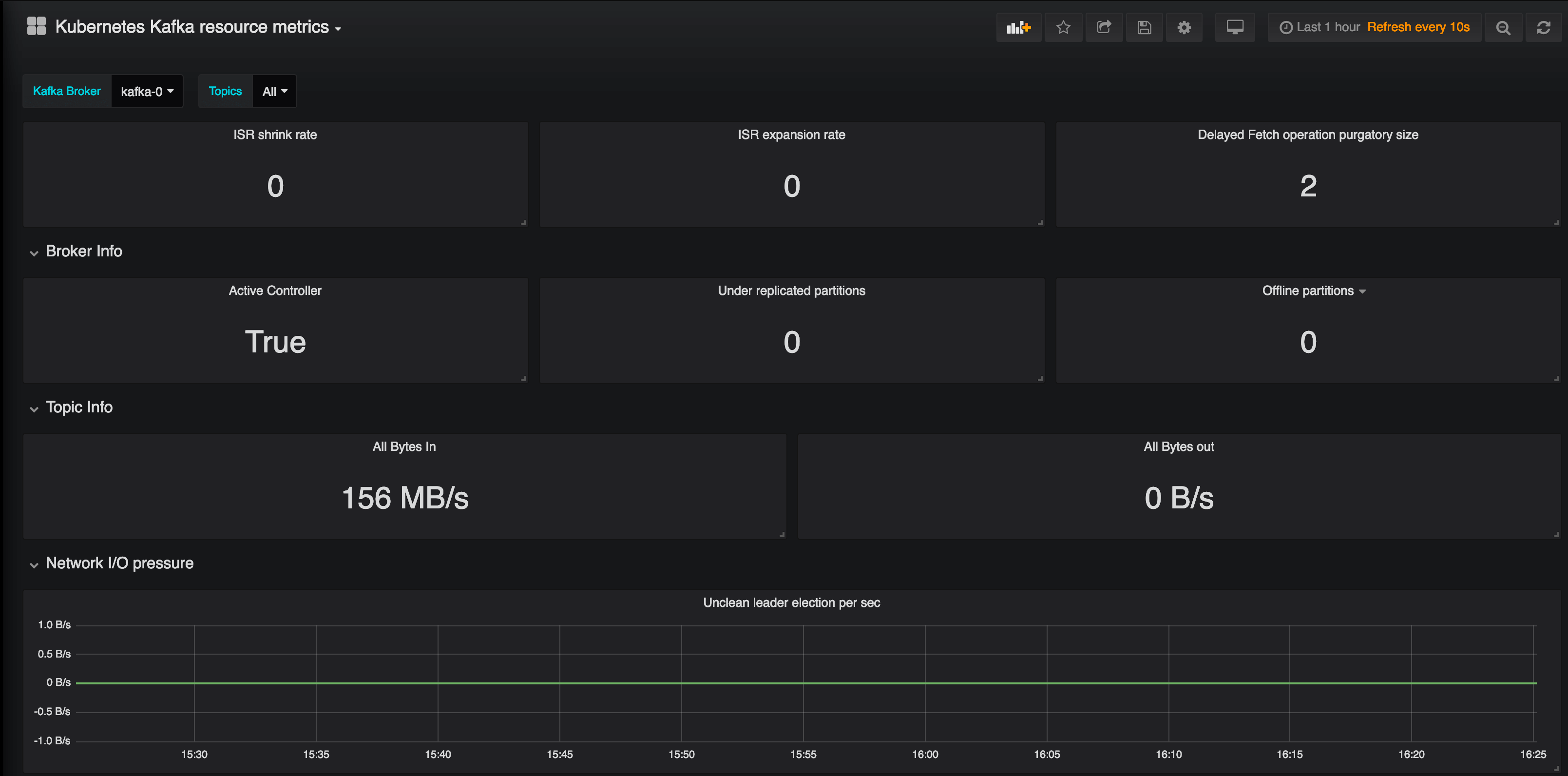
If you go to the default Grafana charts the Spotguide has installed automatically, you will find there’s quite a lot happening behind the scenes; Prometheus will be collecting metrics and those metrics will be available in the form of charts. The charts should show a healthy Kafka ecosystem with a large amount of messages having been transferred. Everything should be working fine, with no under-replicated partitions and all the partitions in sync.
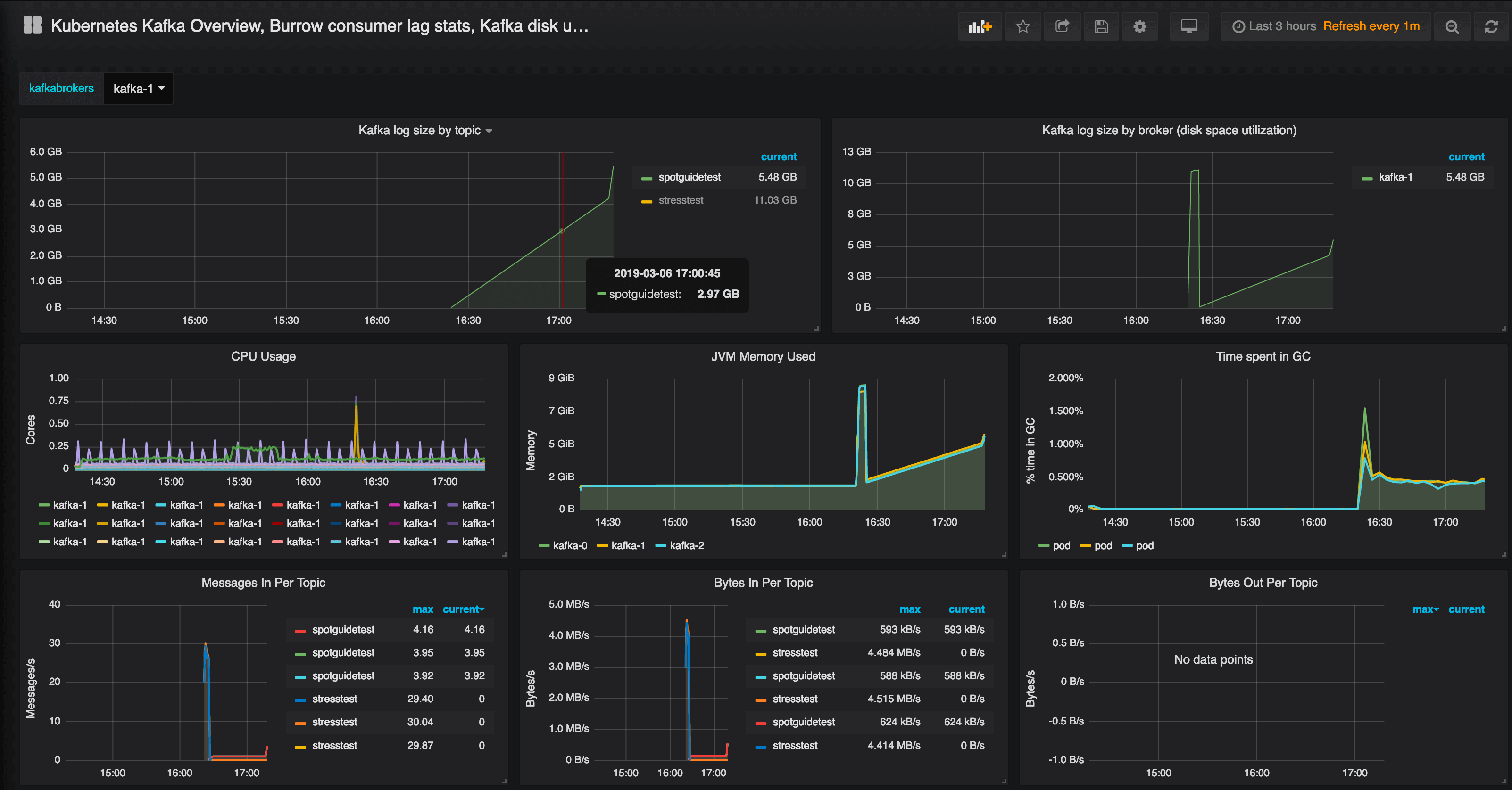
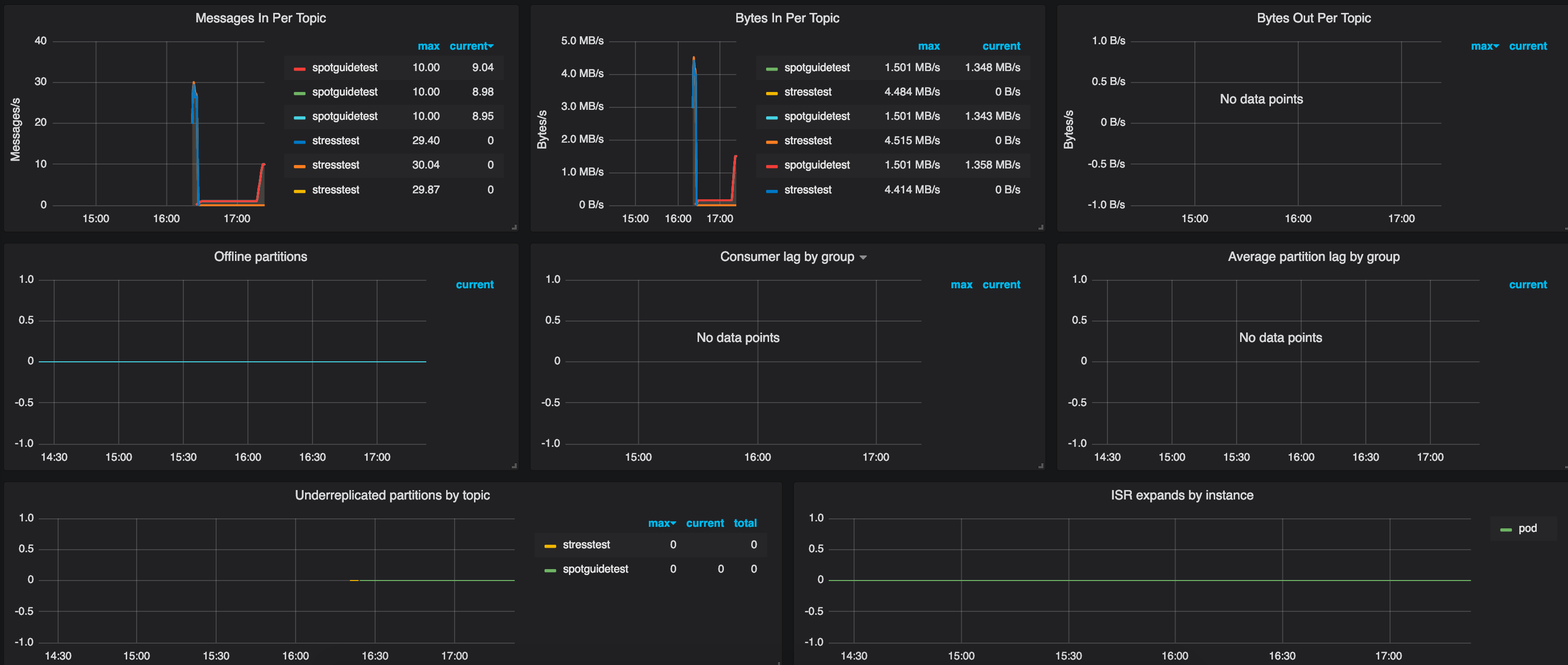
You might want to check the logs, as well, to see that the messages are arriving in the location you have specified.
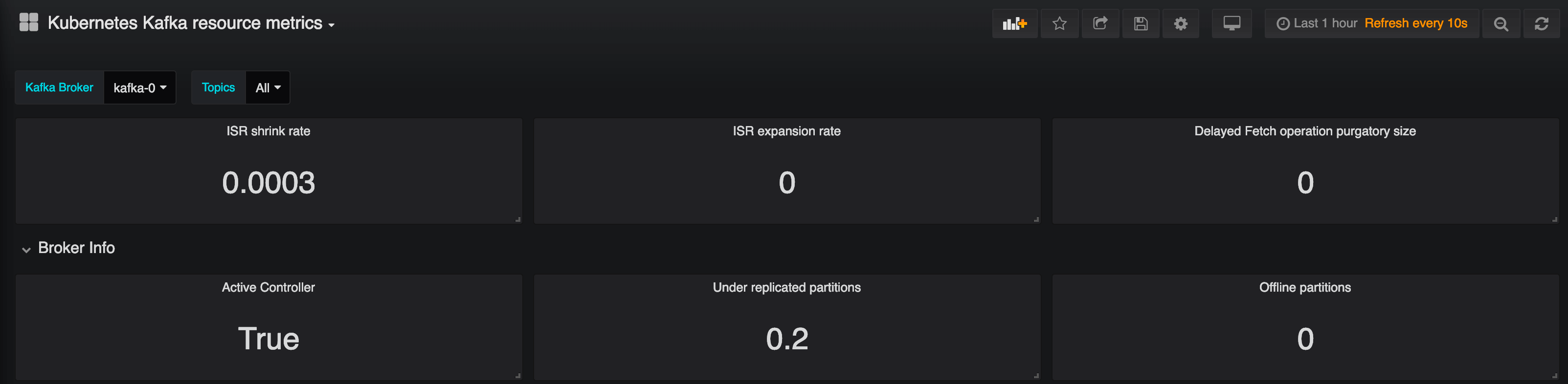
After a while, we may begin to have some problems, in the form of under-replicated partitions. This happens when a broker runs out of disk space, and fails. Kubernetes tries to save the broker by continously restarting it. Luckily, we can consume all transferred messages (no offline partitions yet exist), thanks to our well-chosen replication factor. All this information exists and is made available in the metrics and default charts we provide.
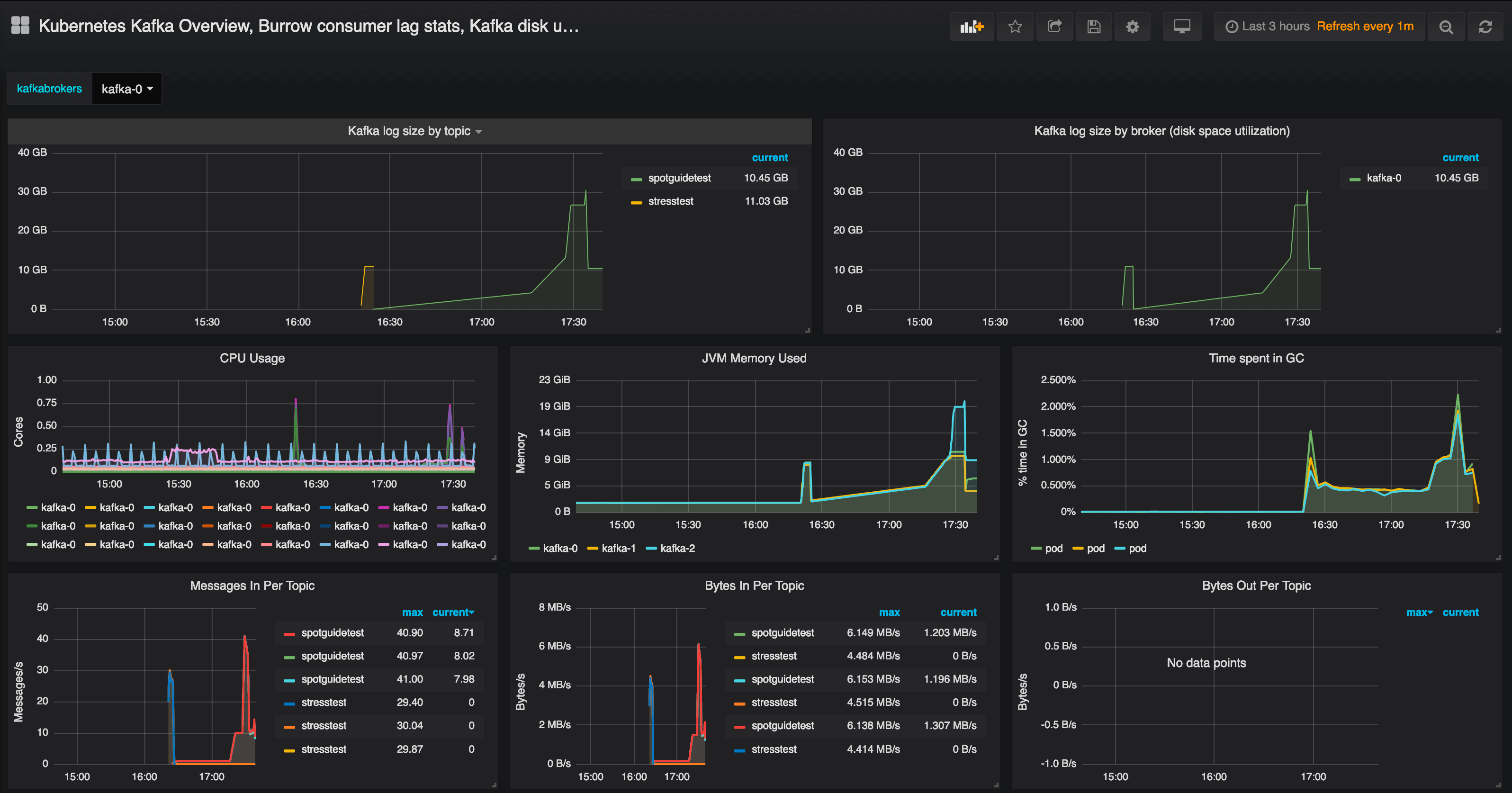
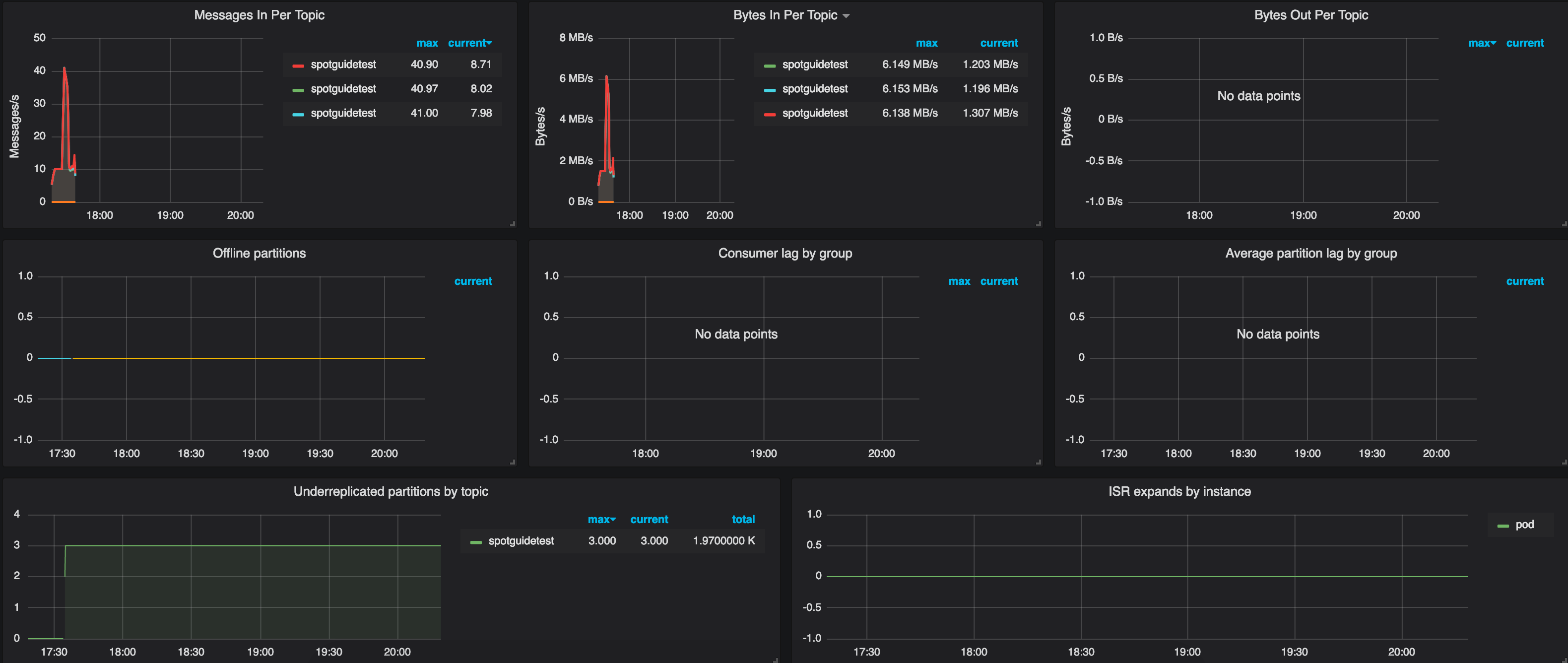
Roadmap 🔗︎
So what’s next? What we’ve just demonstrated is already faster and more convenient than most other options, but is still far from perfect. It’s not perfect, because, when shit hits the proverbial fan, it requires manual intervention, and, at the same time, lacks a few features that may be required by some Kafka developers. Also, it involves some constraints that, when running on Kubernetes, we believe should be handled differently.
The following are all works in progress that will soon be opensourced as part of our Kubernetes operator for Apache Kafka:
- Ability to enable or disable a Schema Registry when creating a Spotguide
- Support for multiple open-source Kafka connectors
- Fine Grained Broker Config support
- Fine Grained Broker Volume support
- Fine Grained upscale and downscale support (this will involve radically different Kubernetes technology/a different approach to all Kafka solutions (including the current state of our operator))
- Intelligent failure management including nodes, brokers and disks
- Istio backed external access using the Banzai Cloud Istio operator
- Open-source Kafka UI support, like this
Finally, you may be wondering why we haven’t opensourced our operator. While it’s already in use beneath the Kafka Spotguide, we believe that if someone opensources a new component it should be considerably better than, or differ considerably from, those that already exist. We are dedicated to, and are working hard on, adding these extra features to our open source Koperator in order to provide the best Kafka experience on Kubernetes. The initial feedback we’ve received from private previews has been outstanding - if you’d like to try it yourself, please subscribe to our beta platform.
Happy streaming!
About Banzai Cloud Pipeline 🔗︎
Banzai Cloud’s Pipeline provides a platform for enterprises to develop, deploy, and scale container-based applications. It leverages best-of-breed cloud components, such as Kubernetes, to create a highly productive, yet flexible environment for developers and operations teams alike. Strong security measures — multiple authentication backends, fine-grained authorization, dynamic secret management, automated secure communications between components using TLS, vulnerability scans, static code analysis, CI/CD, and so on — are default features of the Pipeline platform.