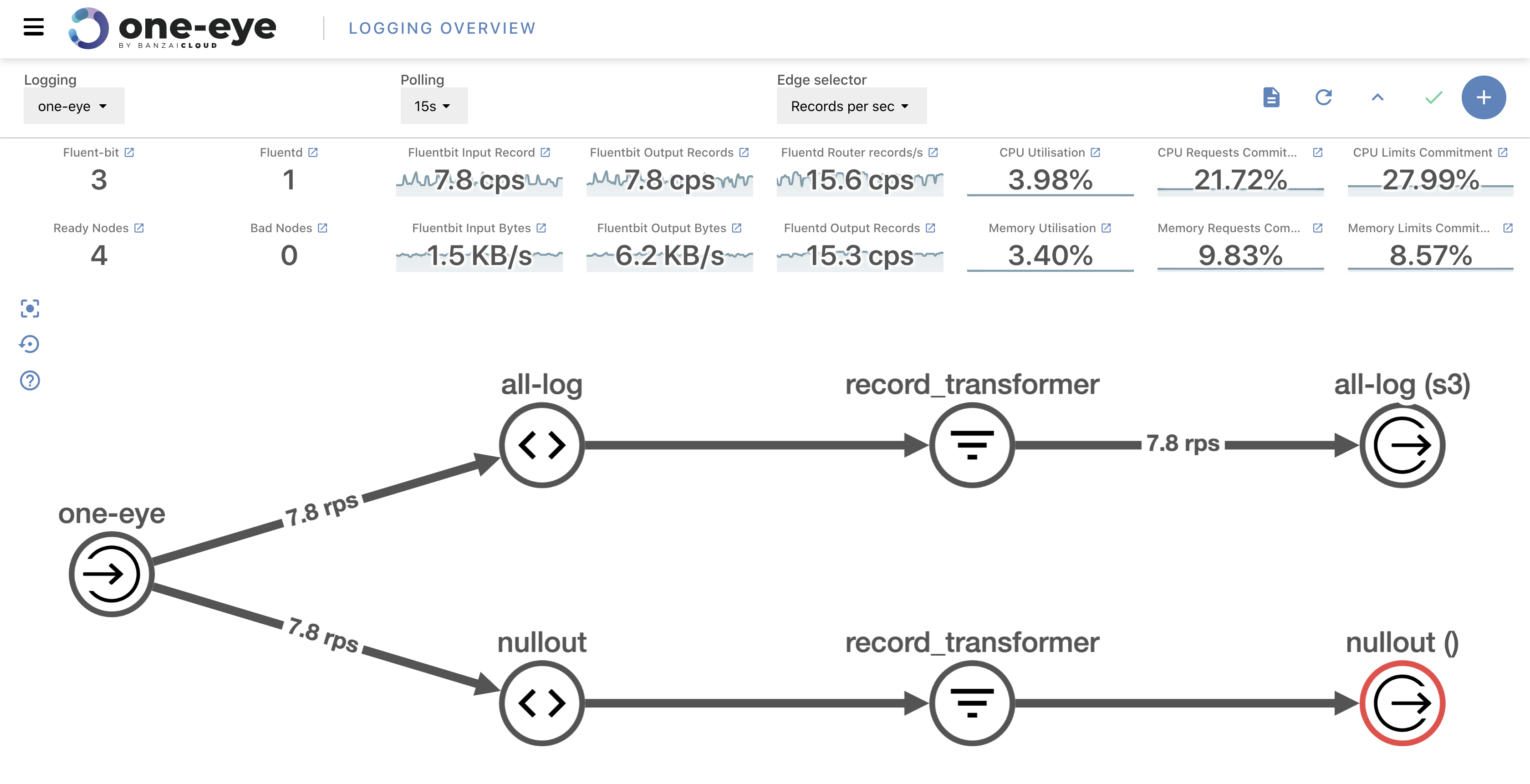
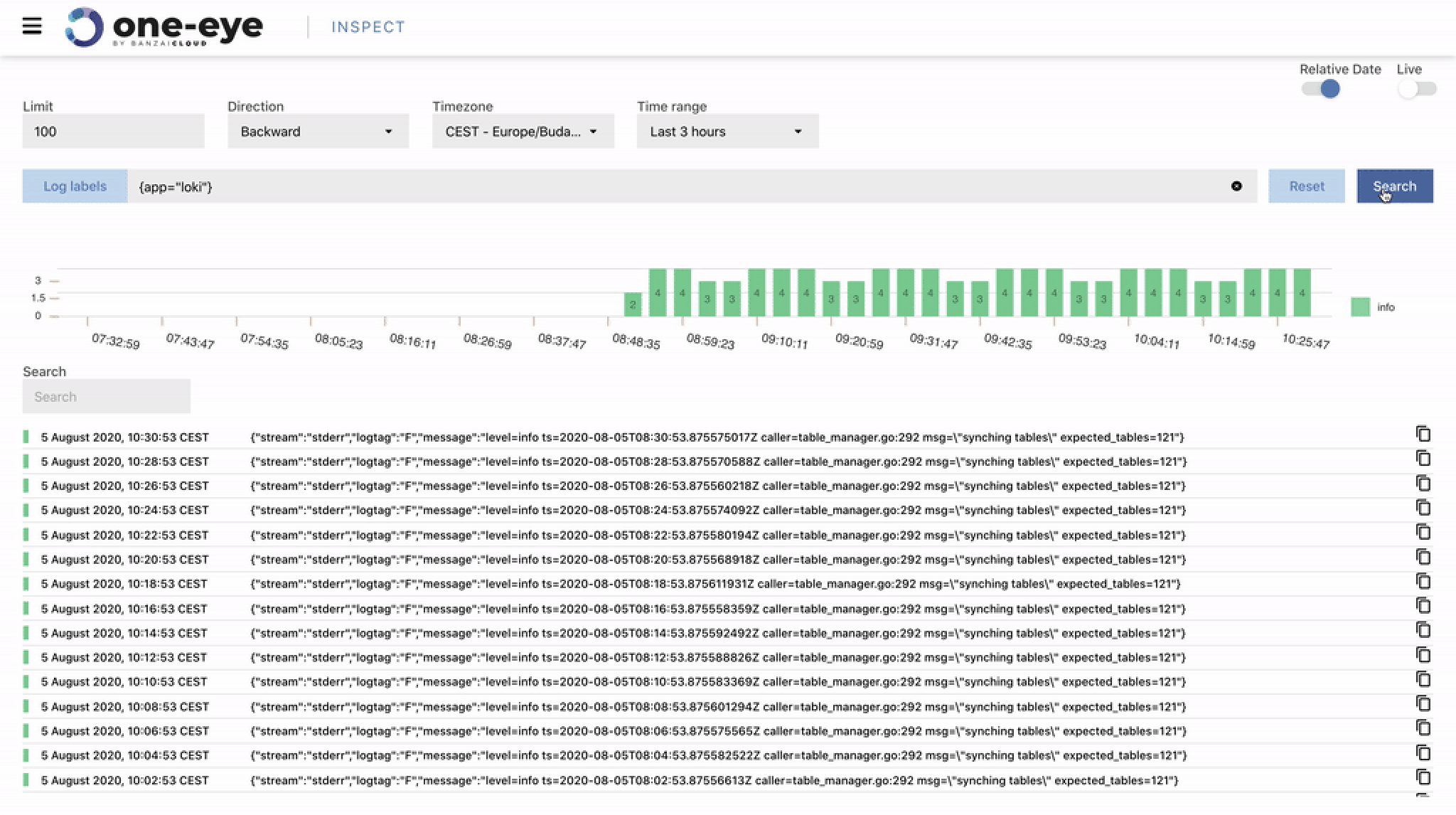
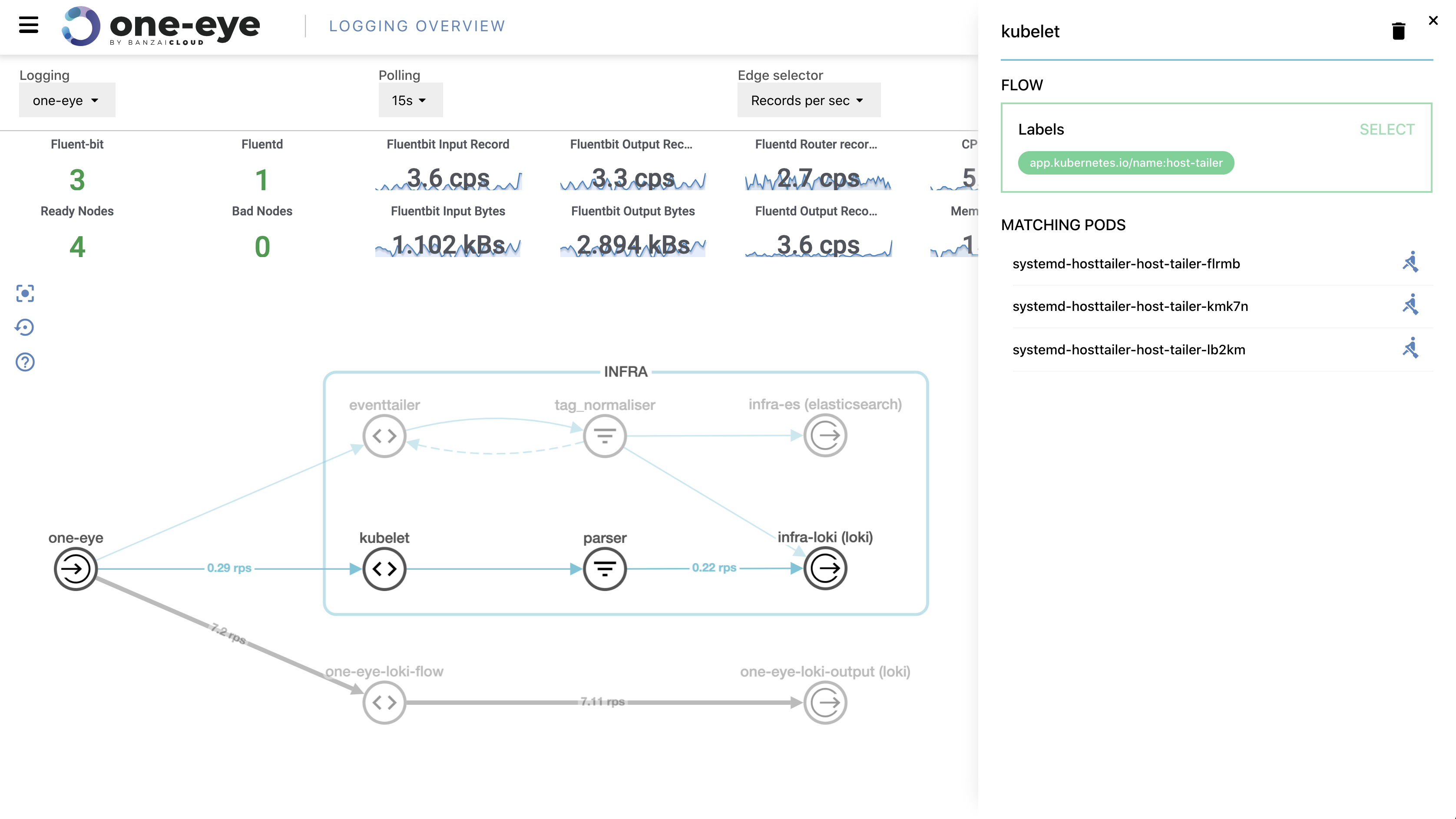
At Banzai Cloud we run multiple Kubernetes clusters deployed with our next generation PaaS, Pipeline, and we deploy these clusters across different cloud providers like AWS, Azure and Google, or on-premise. These clusters are typically launched via the same control plane deployed either to AWS, as a CloudFormation template, or Azure, as an ARM template. And, since we practice what we preach, they run inside Kubernetes as well.
One of the added values to deployments via Pipeline is out-of-the-box monitoring and dashboards through default spotguides for the applications we also support out-of-the-box. For enterprise grade monitoring we chose Prometheus and Grafana, both open source, widely popular, and with a large communities.
Monitoring series:
Monitoring Apache Spark with Prometheus
Monitoring multiple federated clusters with Prometheus - the secure way
Application monitoring with Prometheus and Pipeline
Building a cloud cost management system on top of Prometheus
Because we use large, multi-cloud clusters and deployments, we use federated Prometheus clusters.
Instead of using federated Prometheus clusters we have switched to metric federation using Thanos. Before the 2.0 release of Pipeline and the time when we published this post, Thanos was not available. Today we find Thanos a better and cleaner option. You can read more here: Multi cluster monitoring with Thanos
Prometheus federation 🔗︎
Prometheus is a very flexible monitoring solution wherein each Prometheus server is able to act as a target for another Prometheus server in a highly-available, secure way. By configuring and using federation, Prometheus servers can scrape selected time series data from other Prometheus servers. There are two types of federation scenarios supported by Prometheus; at Banzai Cloud, we use both hierarchical and cross-service federations, but the example below (from the Pipeline control plane) is hierarchical.

A typical Prometheus federation example configuration looks like this:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
As you may know, in Prometheus jobs use the same authentication. That means that monitoring multiple federated clusters, across multiple cloud providers, using the same authentication per cluster or job, is not feasible. Thus, in order to monitor them, we dynamically generate them for each cluster via Pipeline. The end result looks like this:
- job_name: sfpdcluster14
honor_labels: true
params:
match[]:
- '{job="kubernetes-nodes"}'
- '{job="kubernetes-apiservers"}'
- '{job="kubernetes-service-endpoints"}'
- '{job="kubernetes-cadvisor"}'
- '{job="node_exporter"}'
scrape_interval: 15s
scrape_timeout: 7s
metrics_path: /api/v1/namespaces/default/services/monitor-prometheus-server:80/proxy/prometheus/federate
scheme: https
static_configs:
- targets:
- 34.245.71.218
labels:
cluster_name: sfpdcluster14
tls_config:
ca_file: /opt/pipeline/statestore/sfpdcluster14/certificate-authority-data.pem
cert_file: /opt/pipeline/statestore/sfpdcluster14/client-certificate-data.pem
key_file: /opt/pipeline/statestore/sfpdcluster14/client-key-data.pem
insecure_skip_verify: true
...
Prometheus and Kubernetes (the secure way) 🔗︎
As seen above, the remote Kubernetes cluster is accessed through the standard Kubernetes API server, instead of adding an ingress controller to every remote cluster that’s to be monitored. We chose this way of doing things, because, in this case, we can use standard Kubernetes authentication and authorization mechanisms, since Prometheus supports TLS based authentication. As seen in the metrics_path: /api/v1/namespaces/default/services/monitor-prometheus-server:80/proxy/prometheus/federate snippet, this is a standard Kubernetes API endpoint, suffixed with a service name and uri: monitor-prometheus-server:80/proxy/prometheus/federate. The Prometheus server at the top of the topology uses this endpoint to scrape federated clusters and default Kubernetes proxy handles, then dispatches the scrapes to that service.
The config below is the authentication part of the generated setup. The TLS configuration is explained in the following documentation.
tls_config:
ca_file: /opt/pipeline/statestore/sfpdcluster14/certificate-authority-data.pem
cert_file: /opt/pipeline/statestore/sfpdcluster14/client-certificate-data.pem
key_file: /opt/pipeline/statestore/sfpdcluster14/client-key-data.pem
insecure_skip_verify: true
Again, all these are dynamically generated by Pipeline.
Monitoring a Kubernetes service 🔗︎
Monitoring systems need some form of service discovery to work. Prometheus supports different service discovery scenarios: a top-down approach with Kubernetes as its source, or a bottom-up approach with sources like Consul. Since all our deployments are Kubernetes-based, we’ll use the first approach.
Let’s take the pushgateway Kubernetes service definition as our example. Prometheus will scrape this service through annotations, prometheus.io/scrape: "true", and, as a probe, search for the pushgateway name.
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/probe: pushgateway
prometheus.io/scrape: "true"
labels:
app: {{ template "prometheus.name" . }}
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
heritage: {{ .Release.Service }}
release: {{ .Release.Name }}
name: prometheus-pushgateway
spec:
ports:
- name: http
...
selector:
app: prometheus
component: "pushgateway"
release: {{ .Release.Name }}
type: "ClusterIP"
The Prometheus config block below uses the internal Kubernetes service discovery kubernetes_sd_configs. Because this is running in-cluster, and we have provided an appropriate cluster role to the deployment, there is no need to explicitly specify authentication, though we could. After service discovery, we’ll have retained a list of services in which the probe name is pushgateway and scrape is true.
Prometheus can use service discovery out-of-the-box when running inside Kubernetes
- job_name: 'banzaicloud-pushgateway'
honor_labels: true
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: "pushgateway"
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__name__]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: ${1}:${2}
target_label: __address__
As you can see, the annotations are not hardcoded. They’re configured inside the Prometheus relabel configuration section. For example, the following configuration grabs Kubernetes service metadata annotations and, using them, replaces the __metrics_path__ label.
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
We will expand more on the topic of relabels in the next post in this series, using a practical example of how to monitor Spark and Zeppelin and unify metrics names (metrics_name) in a centralized dashboard.
Dashboards 🔗︎
There are lots of dashboarding solutions available, but we chose Grafana. Grafana has great integration with Prometheus and other time series databases, and provides access to useful tools like the PromQL editor, allowing for the creation of amazing dashboards. Just a reminder: “Prometheus provides a functional expression language that lets the user select and aggregate time series data in real time.” PromQL adds some basic statistical functions which we also use, like linear prediction functions that help alert us to unexpected things before they happen.
Instead of using federated Prometheus clusters we have switched to metric federation using Thanos. Before the 2.0 release of Pipeline and the time when we published this post, Thanos was not available. Today we find Thanos a better and cleaner option. You can read more here: Multi cluster monitoring with Thanos