Apache Kafka was designed with a heavy emphasis on fault-tolerance and high-availability in mind, and thus provides different methods of ensuring enterprise-grade resiliency such as:
-
replication factor - which defines how many partition replicas of a topic should be kept, each one being stored on a different broker. A replication factor of N allows for the loss of N-1 brokers. The new brokers will replace the lost brokers until the number of remaining broker(s) reaches the replication factor, or the number of copies of the partitions of a topic.
-
rack awareness - the rack awareness feature spreads replicas of the same partition across different racks. This feature expands Kafka provisions against broker-failure to include rack-failure, mitigating the risk of data loss should all the brokers on a rack fail at once.
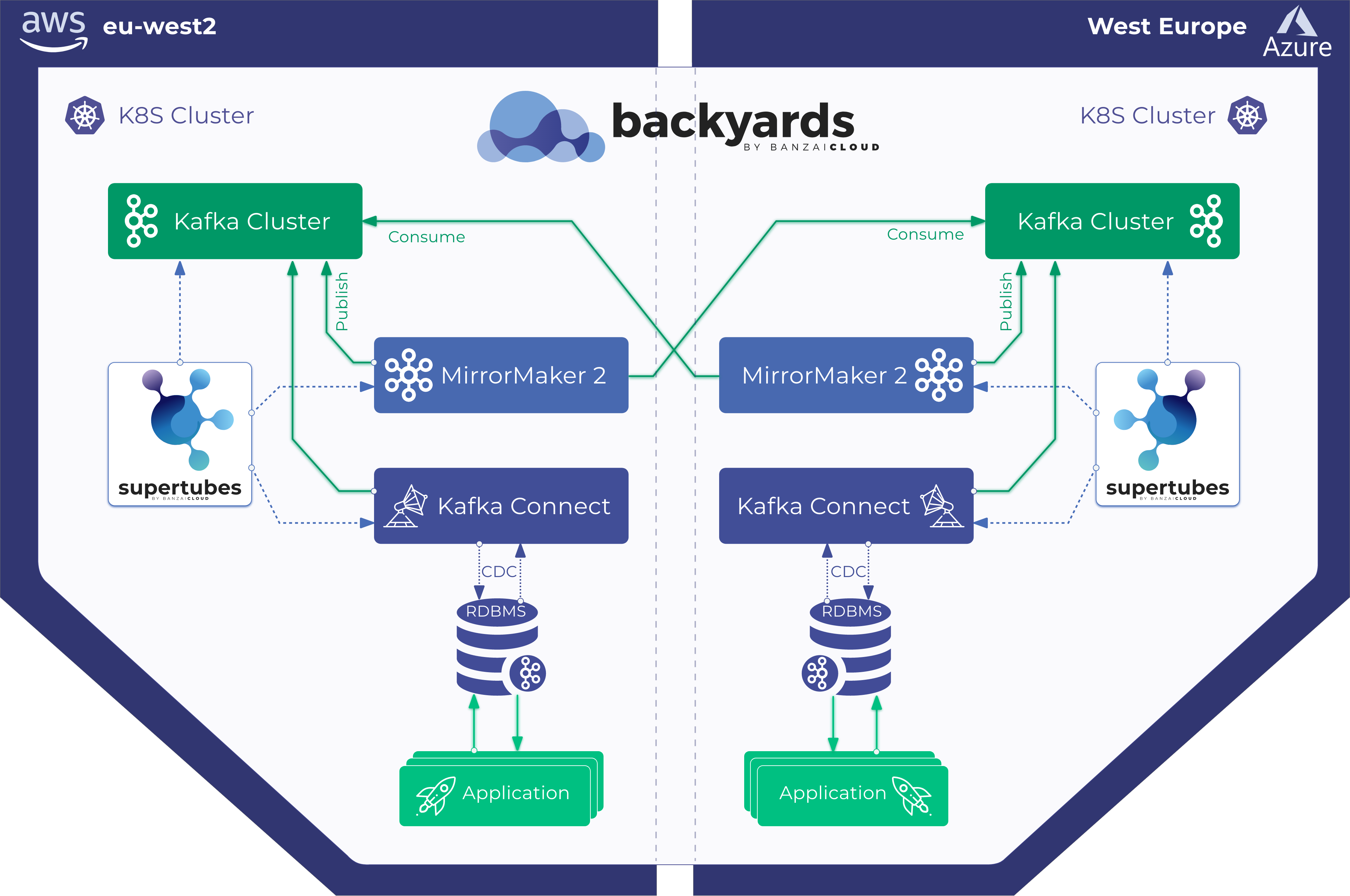
These features alone, allow us to set up Kafka clusters which can tolerate most of the failure event types that might occur in a distributed system. Unfortunately, these do not safeguard against catastrophic events like losing all the brokers that host the replicas of a topic at once, and which result in data loss - this scenario is covered in our Kafka disaster recovery on Kubernetes using MirrorMaker2 blog post.
Our Supertubes product solves this problem for our customers, since it provides disaster recovery for the Kafka clusters it is provisioned on in Kubernetes. Currently, it includes two different disaster recovery methods which can be used, either separately or combined, to achieve the desired level of fault-tolerance. One is based on backing up the volumes used by brokers, and the restore brokers from those backups. The other relies on cross-cluster replication between remote Kafka clusters using MirrorMaker2. In this post we’ll cover disaster recovery based on volume backup and restoration. We explore the method based on MirrorMaker2 in a separate post.
Check out Supertubes in action on your own clusters:
Register for an evaluation version and run a simple install command!
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
Evaluation downloads are temporarily suspended. Contact us to discuss your needs and requirements, and organize a live demo.
supertubes install -a --no-demo-cluster --kubeconfig <path-to-k8s-cluster-kubeconfig-file>or read the documentation for details.
Take a look at some of the Kafka features that we’ve automated and simplified through Supertubes and the Koperator , which we’ve already blogged about:
- Oh no! Yet another Kafka operator for Kubernetes
- Monitor and operate Kafka based on Prometheus metrics
- Kafka rack awareness on Kubernetes
- Running Apache Kafka over Istio - benchmark
- User authenticated and access controlled clusters with the Koperator
- Kafka rolling upgrade and dynamic configuration on Kubernetes
- Envoy protocol filter for Kafka, meshed
- Right-sizing Kafka clusters on Kubernetes
- Kafka disaster recovery on Kubernetes with CSI
- Kafka disaster recovery on Kubernetes using MirrorMaker2
- The benefits of integrating Apache Kafka with Istio
- Kafka ACLs on Kubernetes over Istio mTLS
- Declarative deployment of Apache Kafka on Kubernetes
- Bringing Kafka ACLs to Kubernetes the declarative way
- Kafka Schema Registry on Kubernetes the declarative way
- Announcing Supertubes 1.0, with Kafka Connect and dashboard
Restoring a Kafka broker from a backup on Kubernetes 🔗︎
If all the replicas of a topic are lost due to the simultaneous failure of all the brokers those replicas are distributed over, the messages stored under that topic are gone and can’t be recovered. The failure mechanisms provided by Kafka cannot handle this situation, so we need a solution that gives us the ability to back up the volumes that periodically store broker data. The concept of Container Storage Interface (CSI) to add support for pluggable volumes has already been introduced to Kubernetes. What makes CSI interesting for us? Volume Snapshot and Restore Volume from Snapshot feature has been added to Kubernetes, but is only supported with CSI Volume plugins.
Note: in order to use volume snapshots beside a CSI driver running on the cluster, the following pre-requisites must be met:
- enable flag --allow-privileged=true for kubelet and kube-apiserver
- enable kube-apiserver feature gates --feature-gates=CSINodeInfo=true,CSIDriverRegistry=true,CSIBlockVolume=true,VolumeSnapshotDataSource=true
- enable kubelet feature gates --feature-gates=CSINodeInfo=true,CSIDriverRegistry=true,CSIBlockVolume=true
Quick CSI recap 🔗︎
Kubernetes moves away from the in-tree storage plugins to the CSI driver plugins model as adding support for new volume plugins to Kubernetes was challenging with the former model. In Kubernetes v1.17 the CSI migration (introduced in Kubernetes v1.14 as alpha feature) has been made beta to help the in-tree to CSI migration effort. When CSI migration is enabled, existing stateful deployments and workloads continue to function as they always have; however, behind the scenes Kubernetes hands control of all storage management operations (previously targeting in-tree drivers) to CSI drivers. Since in-tree* volume plugins will be removed completely in future Kubernetes versions most likely the new volume related features will be implemented only in CSI drivers. Just think of the already mentioned volume snapshots and volume restore from snapshot. But there are others like volume cloning and volume expansion, the later one Kafka can benefit from as it makes possible the resizing of the volume under a broker when needed and doesn’t involves a broker configuration change in contrast to attaching additional volumes to broker.
Supertubes leverages volume snapshots to backup and restore persistent volumes used by Kafka broker(s).
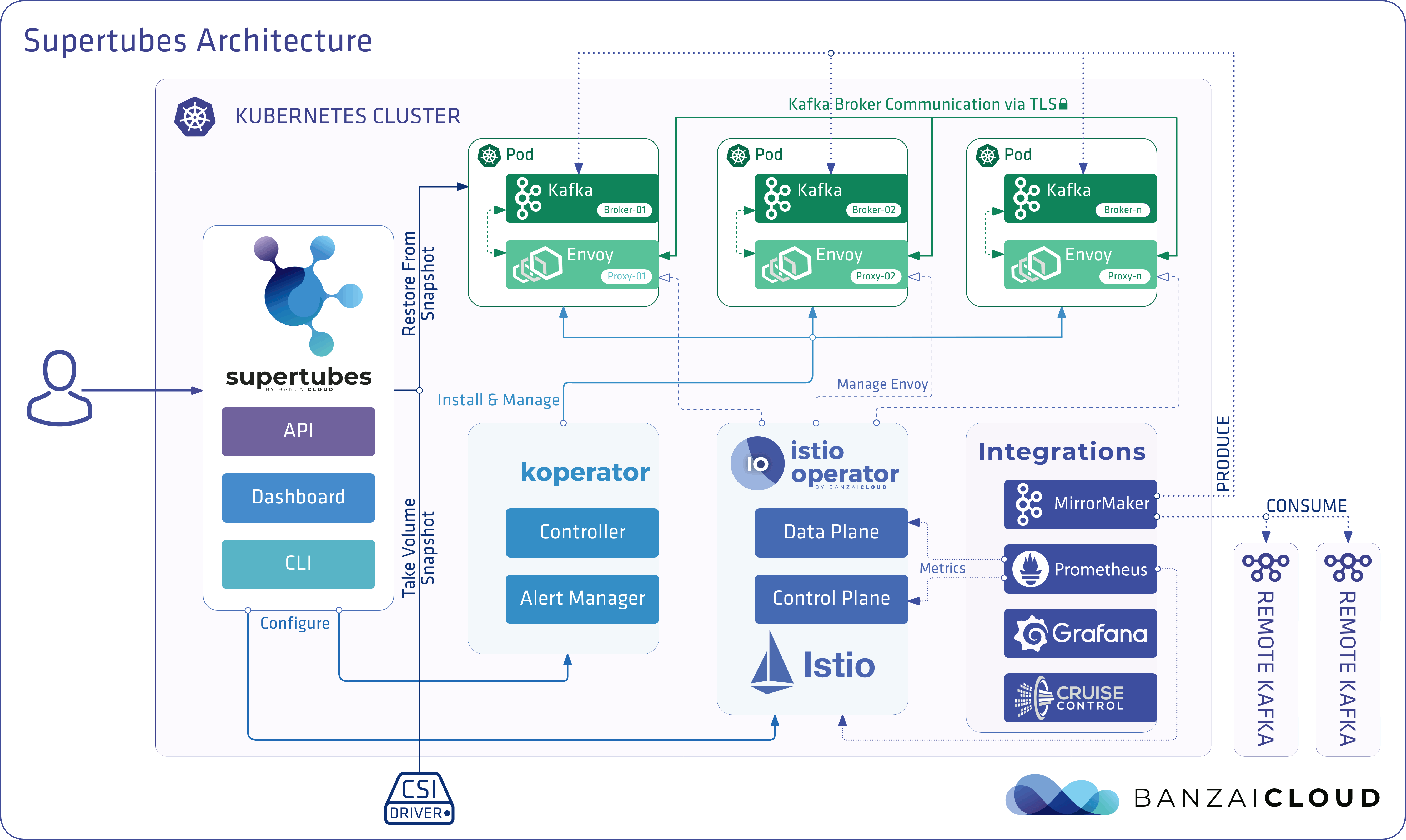
How does it work? Kafka disaster recovery on Kubernetes with CSI! 🔗︎
The user enables periodic backups for a Kafka cluster by creating a KafkaBackup custom resource into the namespace where the Kafka cluster is running.
Example KafkaBackup custom resource:
apiVersion: kafka.banzaicloud.io/v1beta1
kind: KafkaBackup
metadata:
name: kafka-hourly
spec:
clusterRef: kafka # name of the Kafka cluster this backup is for
schedule: "@every 1h" # run backup every hour
retentionTime: "12h" # delete backups older than 12 hours
startingDeadlineSeconds: 300 # do not run backup of missed scheduled time by more than 300 seconds
volumeSnapshotClassName: "csi-aws-vsc"- clusterRef - the name of the Kafka cluster this backup is for
- schedule - the schedule in Cron format
- retentionTime - (optional) the amount of time the backups will remain available for restoration in the format of a sequence of decimals, each with optional fraction and unit suffixes, such as “300ms” or “2h45m”. Valid time units are “ns”, “us”, “ms”, “s”, “m”, “h”. If not set, backups are not deleted
- startingDeadlineSeconds - (optional) the deadline in seconds for starting a job that misses its scheduled time for any reason
- volumeSnapshotClassName - the name of the
VolumeSnapshotClassavailable on the Kubernetes cluster - suspend - (optional) controls whether to suspend subsequent backup executions, but does not apply to executions that have already started. Defaults to false
Supertubes creates volume snapshots from all the persistent volumes used by Kafka brokers to store data according to the schedule specified in the KafkaBackup custom resource. In the event of losing a persistent volume that stores Kafka broker data, Supertubes provisions a new Persistent Volume in place of the lost one and restores data from the most recent snapshot that was taken from the lost Persistent Volume, if any are available.
A volume snapshot represents a point-in-time copy of a volume. This means that the restored Persistent Volume may not contain most of the recent messages that have been ingested after snapshot creation was initiated. Thus, our restored broker may be missing some of the most recent messages. The missing messages can be synced either from other brokers, provided these have a replica of the missing messages, or from a remote Kafka cluster, which we’ll cover how to do in a separate post - the same one in which we’ll present disaster recovery using MirrorMaker2.
To better understand this, let’s look at a few sample scenarios:
- A topic with one partition and a replication factor of one
- If the broker that’s the partition leader goes down (let’s assume for simplicity’s sake that this broker hosts no other partitions of any other topic), no new messages can be ingested by that topic. When this broker is restored from a snapshot, all the partitions will reflect the state in which that snapshot was taken. The messages that were ingested after the snapshot was taken and before the broker died are lost and can’t be recovered.
- A topic with one partition and a replication factor of two
- if the broker that’s the partition leader is lost, the other broker with the replica is promoted to leader. After the lost broker is recovered from the snapshot, it becomes a follower with some of its data preloaded. Thus it will start fetching the missing messages from the new leader.
- If both the leader and follower are lost, this is, in essence, the same scenario as 1.1.
- topic with two partitions and replication factor two
- if all partition leaders and followers are lost. This is the same scenario as in 1.1.
- if all brokers are lost but one, then this is the same scenario as 2.1.
Showtime 🔗︎
It’s time to explore this method of disaster recovery through a simple example. Since the aforementioned feature gates required by the CSI driver are enabled by default to start from Kubernetes version 1.17, we are going to provision a cluster using Kubernetes version 1.17 on AWS, using our hybrid cloud container management platform, Banzai Cloud Pipeline and PKE, our CNCF certified Kubernetes distribution.
Note that with Banzai Cloud Pipeline, you can provision Kubernetes clusters across five clouds and on-oprem (VMware, bare metal)
Install Supertubes CLI 🔗︎
Register for an evaluation version and run the following command to install the CLI tool:
As you might know, Cisco has recently acquired Banzai Cloud. Currently we are in a transitional period and are moving our infrastructure. Contact us so we can discuss your needs and requirements, and organize a live demo.
Evaluation downloads are temporarily suspended. Contact us to discuss your needs and requirements, and organize a live demo.
Deploy CSI driver to our PKE cluster 🔗︎
In accordance with the Amazon Elastic Block Store (EBS) CSI driver set up the CSI driver and create a StorageClass, as well as a SnapshotClass that uses the CSI driver.
Deploy Supertubes to our PKE cluster 🔗︎
supertubes install -a --no-democluster -c <path-to-k8s-cluster-kubeconfig-file>
Provision a Kafka cluster 🔗︎
supertubes cluster create -n kafka -c <path-to-k8s-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/koperator/master/config/samples/simplekafkacluster_ebs_csi.yaml
supertubes cluster get -n kafka --kafka-cluster kafka -c <path-to-k8s-cluster-kubeconfig-file>
Create a topic 🔗︎
Now we’ll create a topic with one partition and a replication factor of one.
supertubes cluster topic create -n kafka --kafka-cluster kafka -c <path-to-k8s-cluster-kubeconfig-file> -f- <<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: my-topic
namespace: kafka
spec:
name: my-topic
partitions: 1
replicationFactor: 1
config:
"retention.ms": "28800000"
"cleanup.policy": "delete"
EOF
Write messages to the topic we just created 🔗︎
kubectl apply -n kafka -f- <<EOF
apiVersion: v1
kind: Pod
metadata:
name: kafkacat
spec:
containers:
- name: kafka-test
image: "solsson/kafkacat:alpine"
# Just spin & wait forever
command: [ "/bin/bash", "-c", "--" ]
args: [ "while true; do sleep 3000; done;" ]
EOF
kubectl exec -n kafka -it kafkacat bash
kafkacat -b kafka-all-broker:29092 -P -t my-topic
hello
there
Verify that we can read back the messages, and which broker is the partition leader for my-topic.
kafkacat -b kafka-all-broker:29092 -C -t my-topic -c2
hello
there
Metadata for my-topic (from broker -1: kafka-all-broker:29092/bootstrap):
3 brokers:
broker 0 at kafka-0.kafka.svc.cluster.local:29092 (controller)
broker 2 at kafka-2.kafka.svc.cluster.local:29092
broker 1 at kafka-1.kafka.svc.cluster.local:29092
1 topics:
topic "my-topic" with 1 partitions:
partition 0, leader 2, replicas: 2, isrs: 2Broker 2 is the partition leader.
Enable periodic backups for the Kafka cluster 🔗︎
supertubes cluster backup create -n kafka --kafka-cluster kafka --snapshot-class csi-aws-vsc --backup-name test-backup --schedule "@every 15m" --retention-time "12h" --starting-deadline-seconds 300 -c <path-to-k8s-cluster-kubeconfig-file>
Wait fifteen minutes until the first backup is executed, and verify that the volume snapshots were created, particularly of broker 2, which is the partition leader for our single partition topic my-topic.
kubectl get volumesnapshot -n kafka -l brokerId=2
NAME AGE
kafka-2-storagetngcc-20200221-190533 26m
kafka-2-storagetngcc-20200221-192033 11m
Stop broker 2 🔗︎
To simulate the complete loss of a broker, we’ll first stop the operator so that we can delete the broker 2 pod and its attached volumes.
kubectl scale deployment -n kafka kafka-operator-operator --replicas=0
kubectl delete pod -n kafka -lkafka_cr=kafka,brokerId=2
kubectl delete pvc -n kafka -lkafka_cr=kafka,brokerId=2
Now let’s check the status of the my-topic topic in Kafka.
kafkacat -b kafka-all-broker:29092 -L -t my-topic
Metadata for my-topic (from broker -1: kafka-all-broker:29092/bootstrap):
2 brokers:
broker 0 at kafka-0.kafka.svc.cluster.local:29092 (controller)
broker 1 at kafka-1.kafka.svc.cluster.local:29092
1 topics:
topic "my-topic" with 1 partitions:
partition 0, leader -1, replicas: 2, isrs: 2, Broker: Leader not availableAs we can see, there are no partition leader brokers for my-topic also no messages are returned by kafkacat from this topic.
Restore broker 2 from a snapshot 🔗︎
Start the operator, which will note that broker 2 is missing and will therefore create a new broker pod. Because Supertubes is aware of the backups created for broker 2, it will seamlessly restore the volume for the new broker 2 instance from the volume snapshot - no user intervention required.
kubectl scale deployment -n kafka kafka-operator-operator --replicas=1
Wait for the new broker 2 pod to come up and check my-topic again.
kafkacat -b kafka-all-broker:29092 -C -t my-topic -c2
hello
there
Supertubes features and roadmap 🔗︎
Supertubes comes with the following set of key features 🔗︎
- Kafka cluster management
- Broker management
- Topic management
- Zookeeper cluster provisioning
- Expose Cruise Control UI
- Runs all deployed services inside of Istio Mesh, which provides:
- Secure communication using mTLS between deployed services (Kafka, Cruise Control, Zookeeper, MirrorMaker2), enforced at the infrastructure layer
- Secure cross-cluster communication between remote Kafka clusters using mTLS via MirrorMaker2 (also enforced at the infrastructure layer)
- Automatic cert renewal used for TLS
- Better performance as Istio provided TLS is faster than the built-in Java TLS algorithm
- Disaster recovery
- Prometheus service monitors for deployed services
Roadmap 🔗︎
- Zookeeper disaster recovery
- Rollback from rolling upgrade failure
- Restore from backup on new Kubernetes cluster
- Audit and tracing
- Observability and management dashboard
About Supertubes 🔗︎
Banzai Cloud Supertubes (Supertubes) is the automation tool for setting up and operating production-ready Apache Kafka clusters on Kubernetes, leveraging a Cloud-Native technology stack. Supertubes includes Zookeeper, the Koperator , Envoy, Istio and many other components that are installed, configured, and managed to operate a production-ready Kafka cluster on Kubernetes. Some of the key features are fine-grained broker configuration, scaling with rebalancing, graceful rolling upgrades, alert-based graceful scaling, monitoring, out-of-the-box mTLS with automatic certificate renewal, Kubernetes RBAC integration with Kafka ACLs, and multiple options for disaster recovery.