Kafka security on Kubernetes, automated
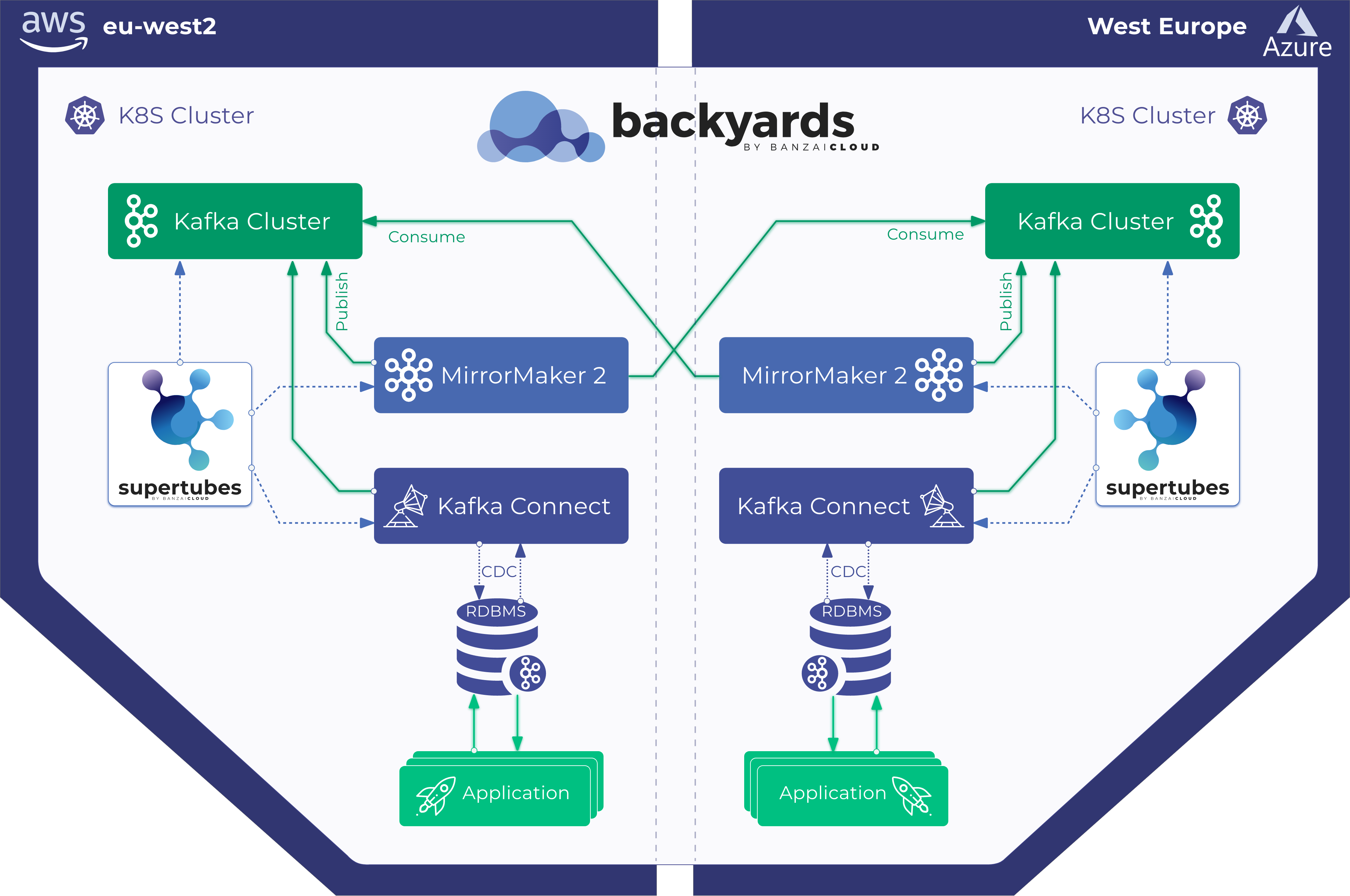
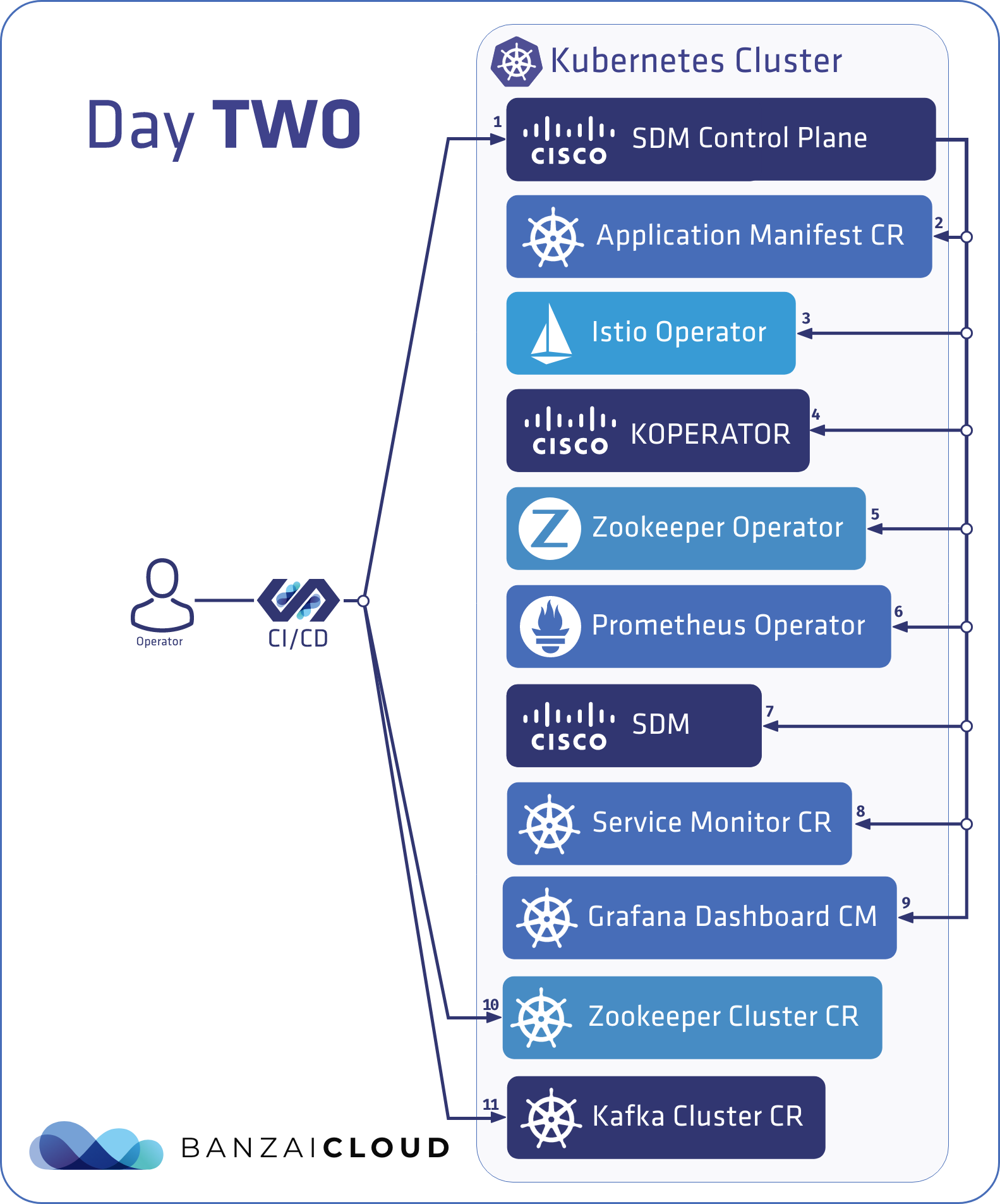
Two weeks ago we introduced our Kafka Spotguide for Kubernetes - the easiest way to deploy and operate Apache Kafka on Kubernetes. Since then, it’s been integrated into our application and DevOps container management platform, Pipeline, among other spotguides such as Spark on Kubernetes, Zeppelin, NodeJS and Golang, just to name a few.
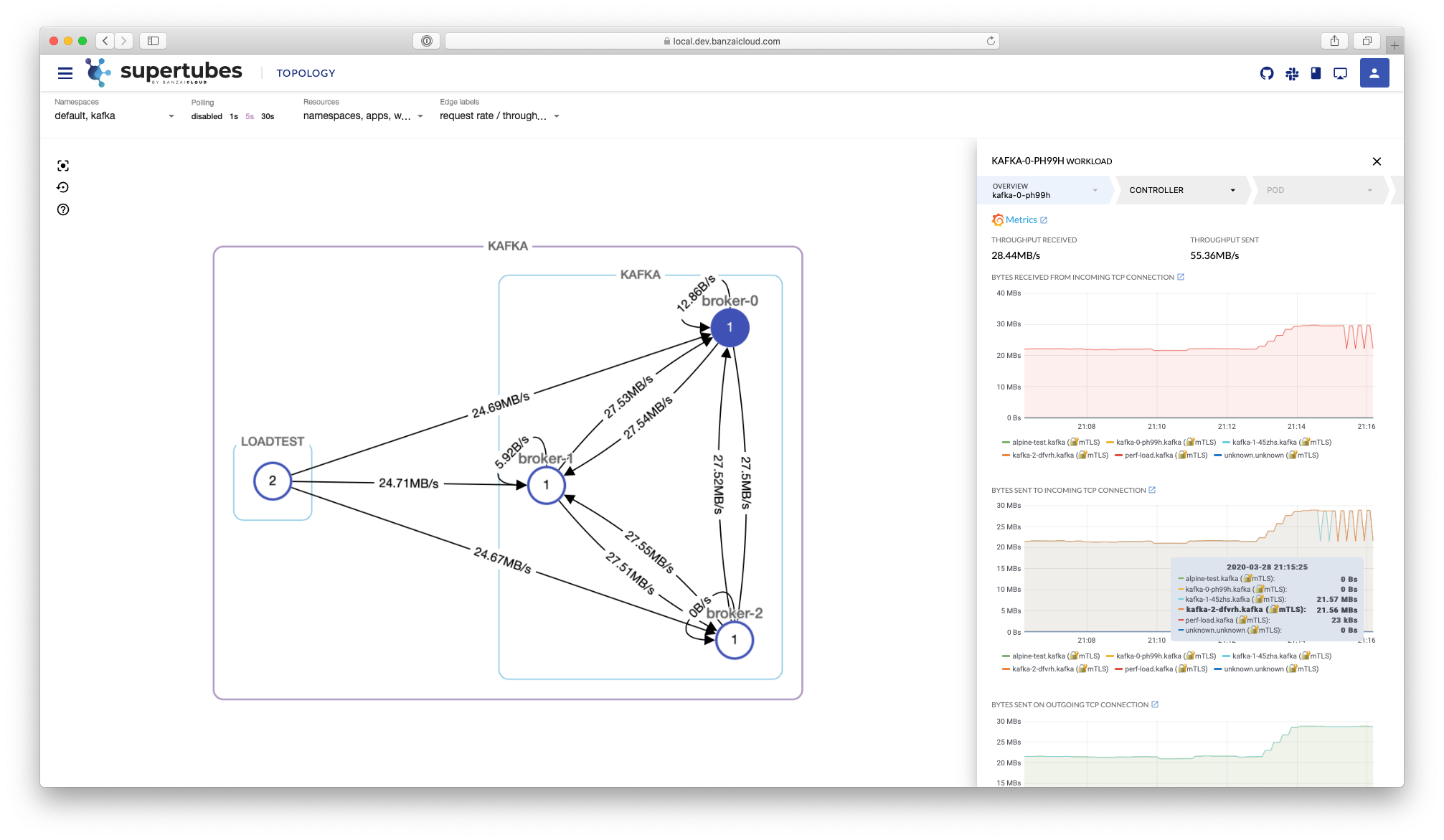
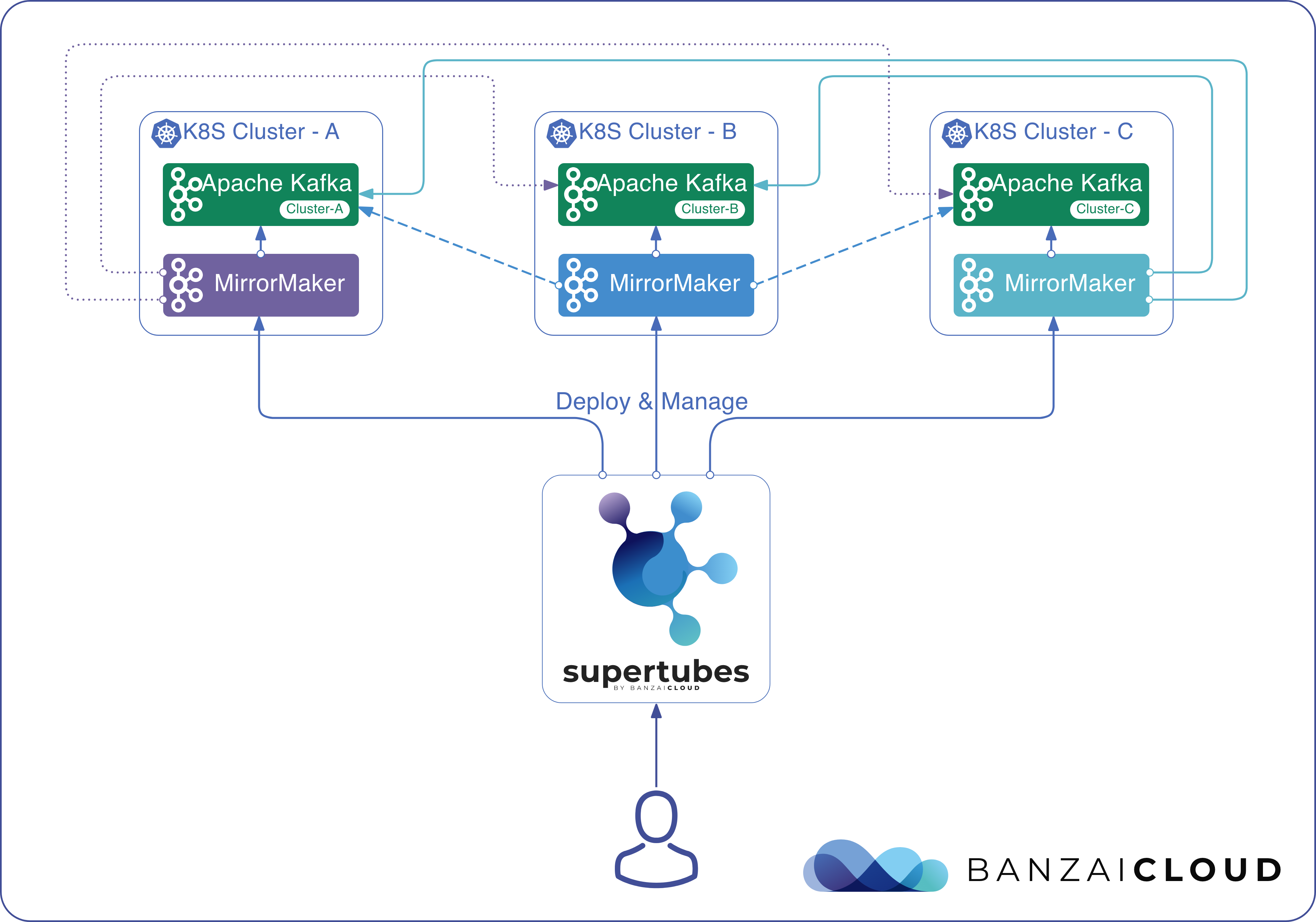
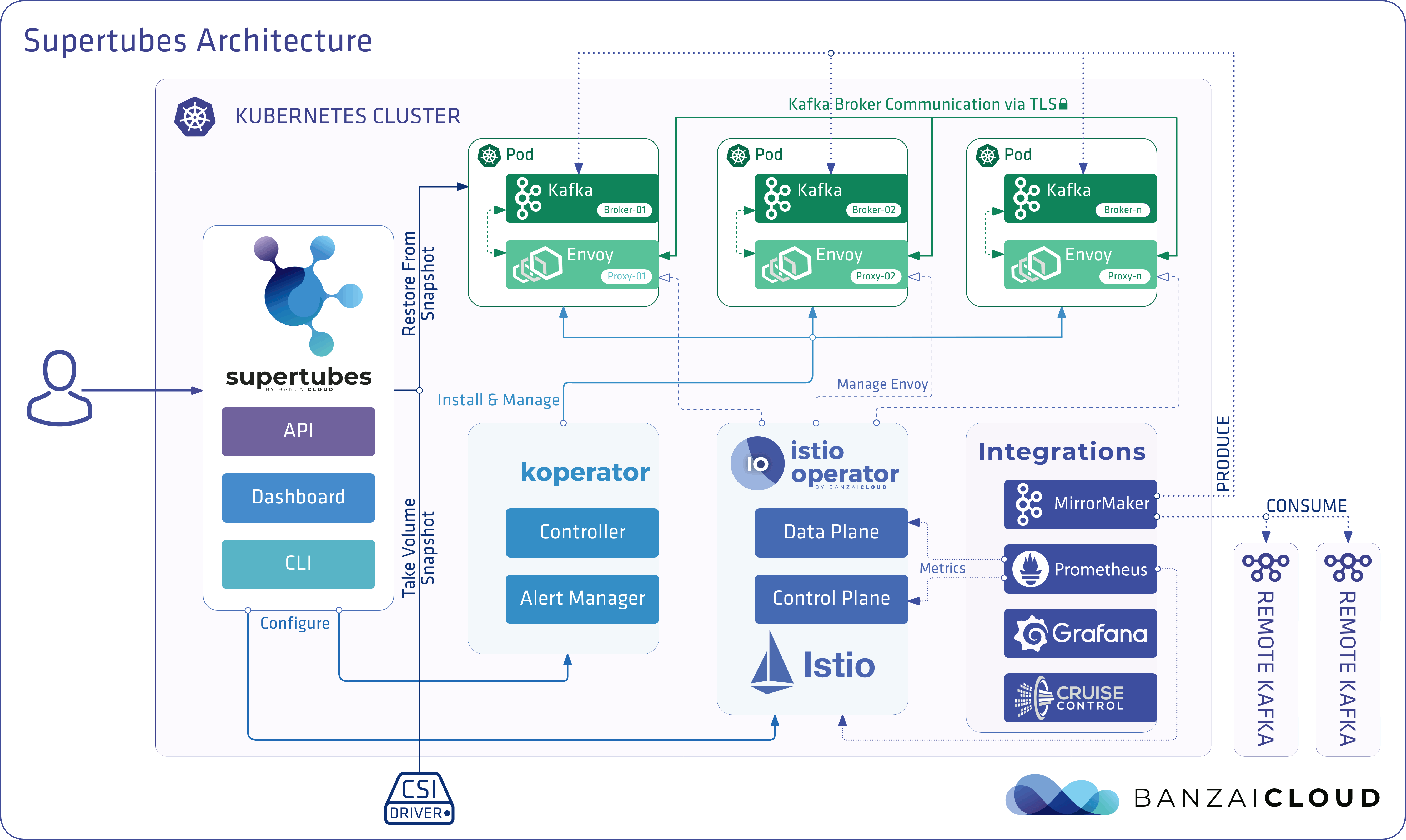
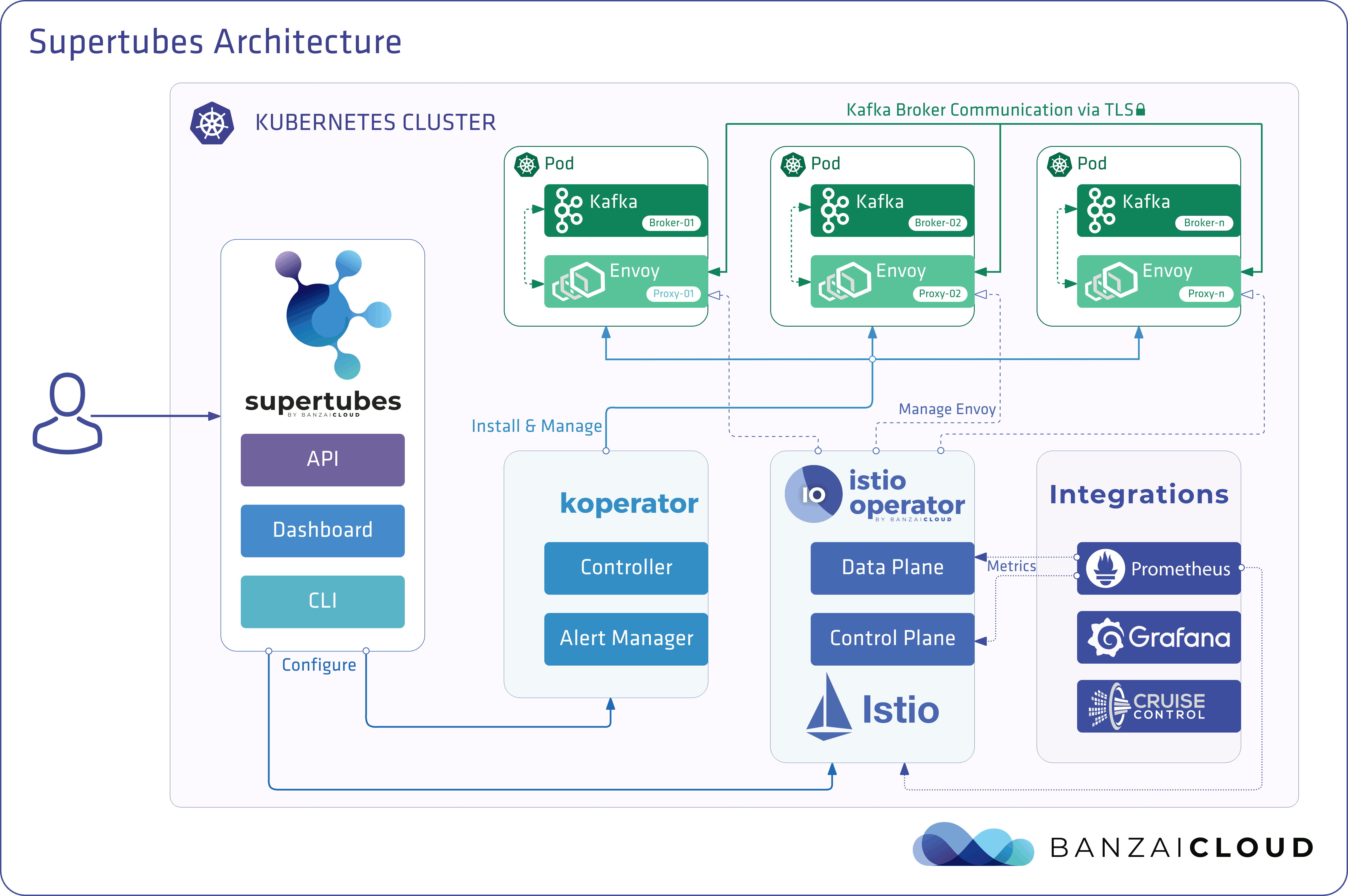
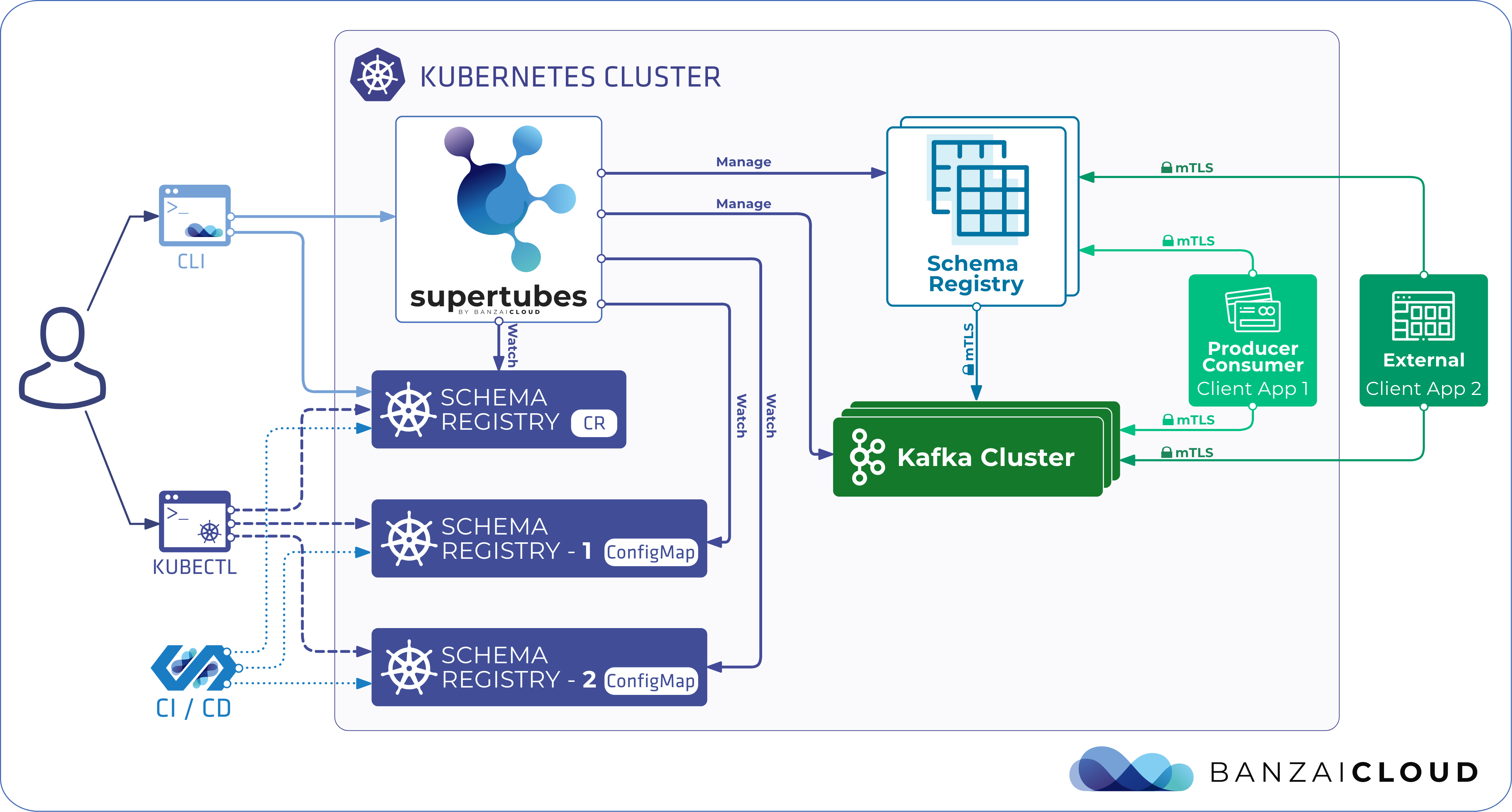
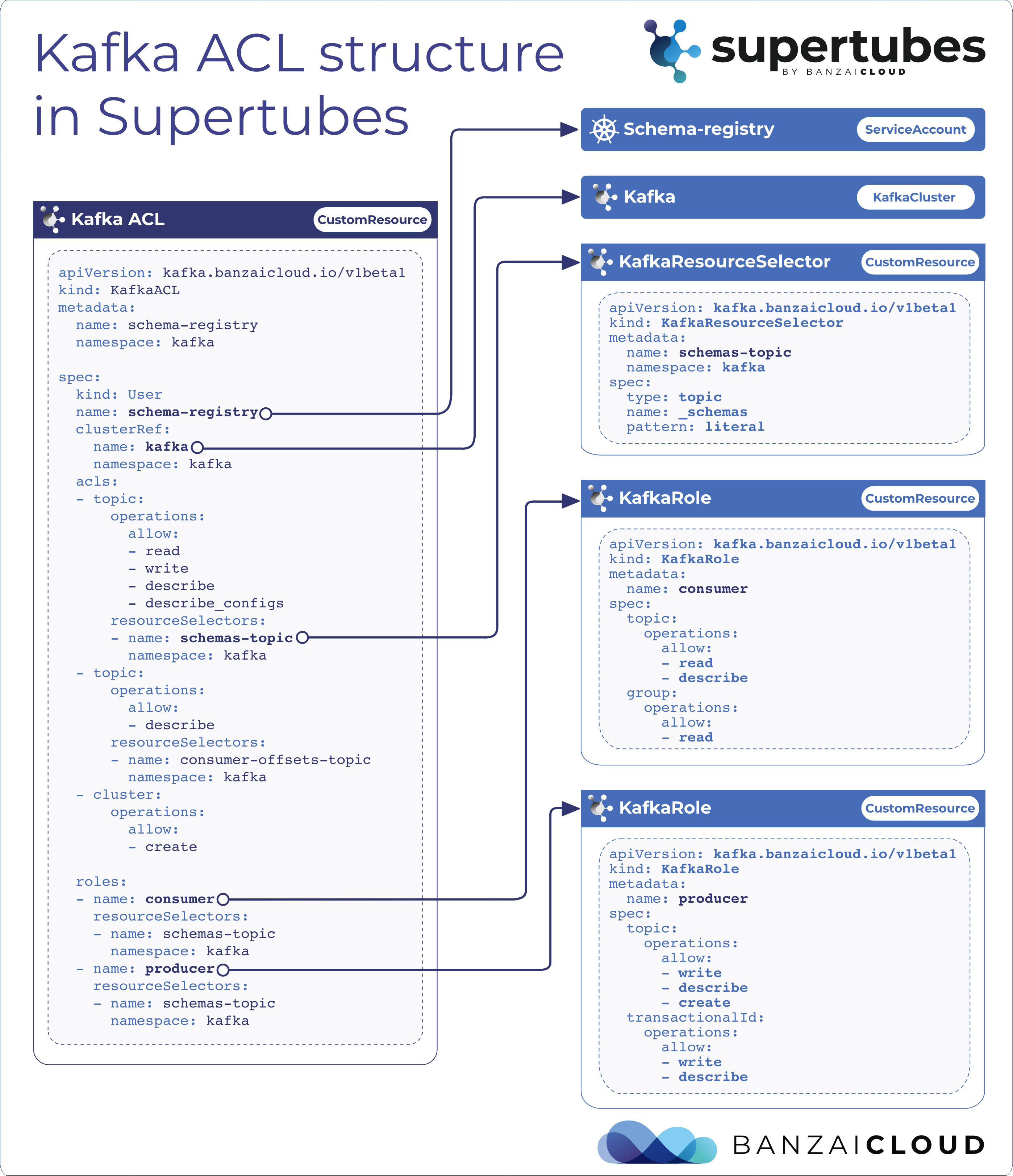
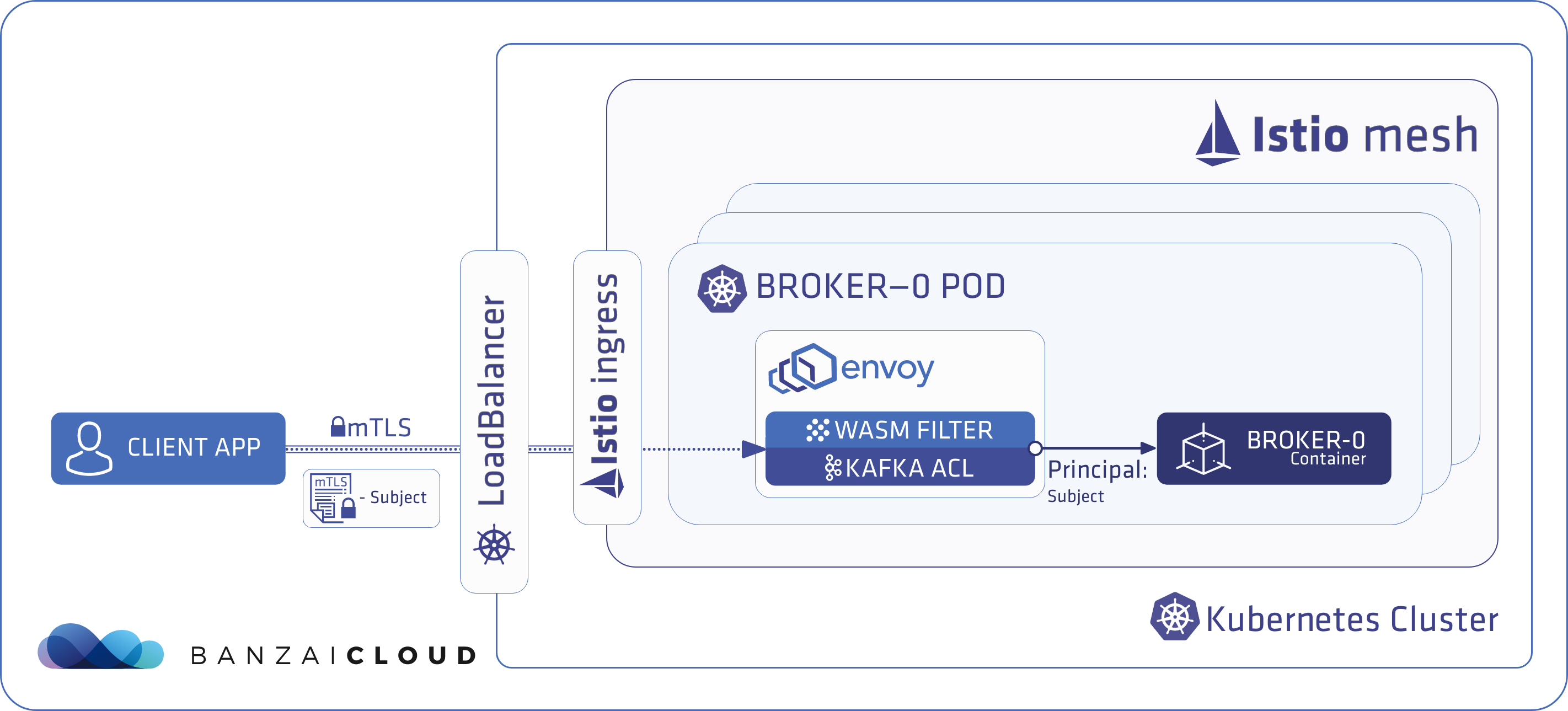
Because we’ve already met our goal of making it easy set up a Kafka cluster on Kubernetes with just few clicks, and in less than ten minutes - provisioning and operating its entire infrastructure, both in Kubernetes and Kafka - we’ve shifted our focus to Kafka security.
READ ARTICLE


Mon, Apr 1, 2019