

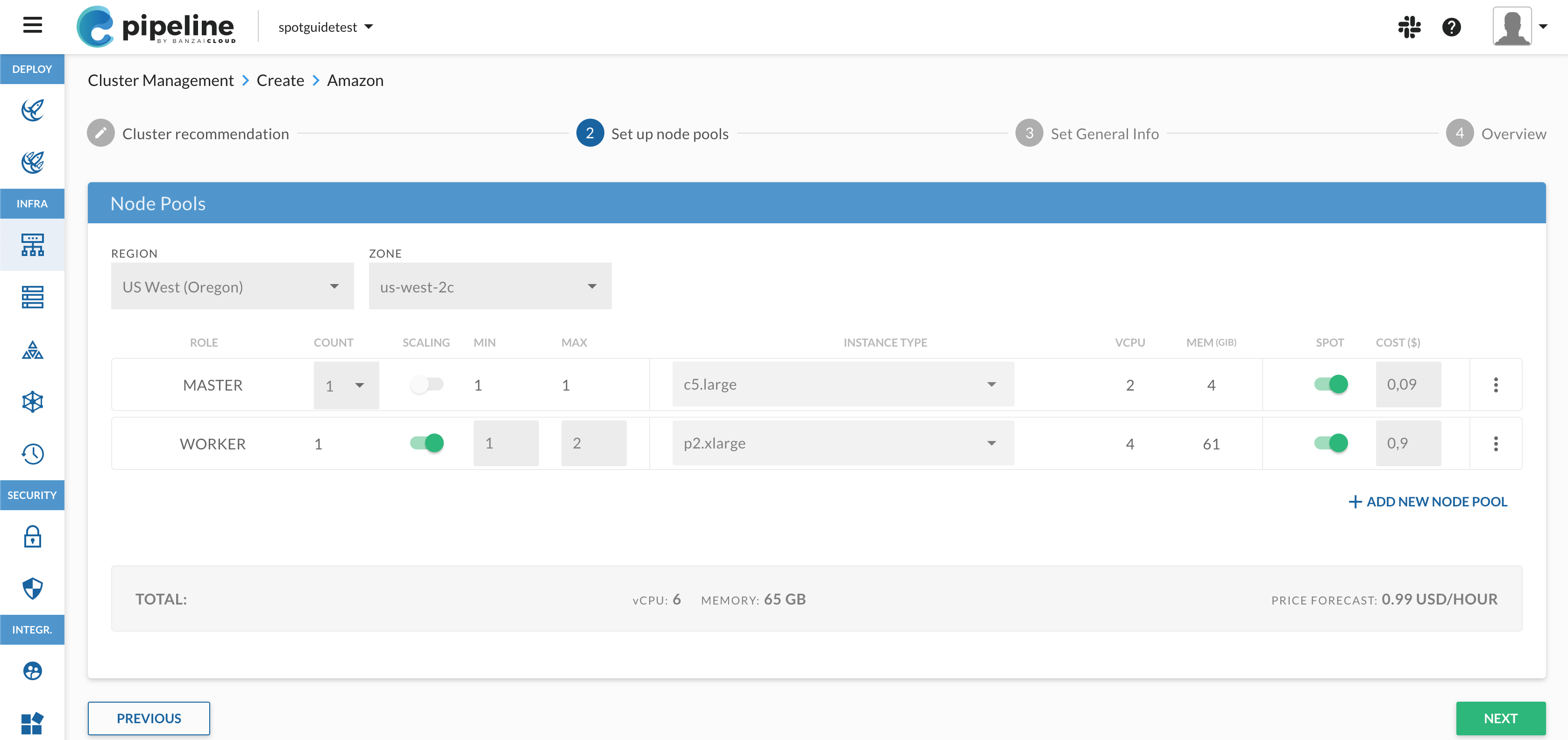
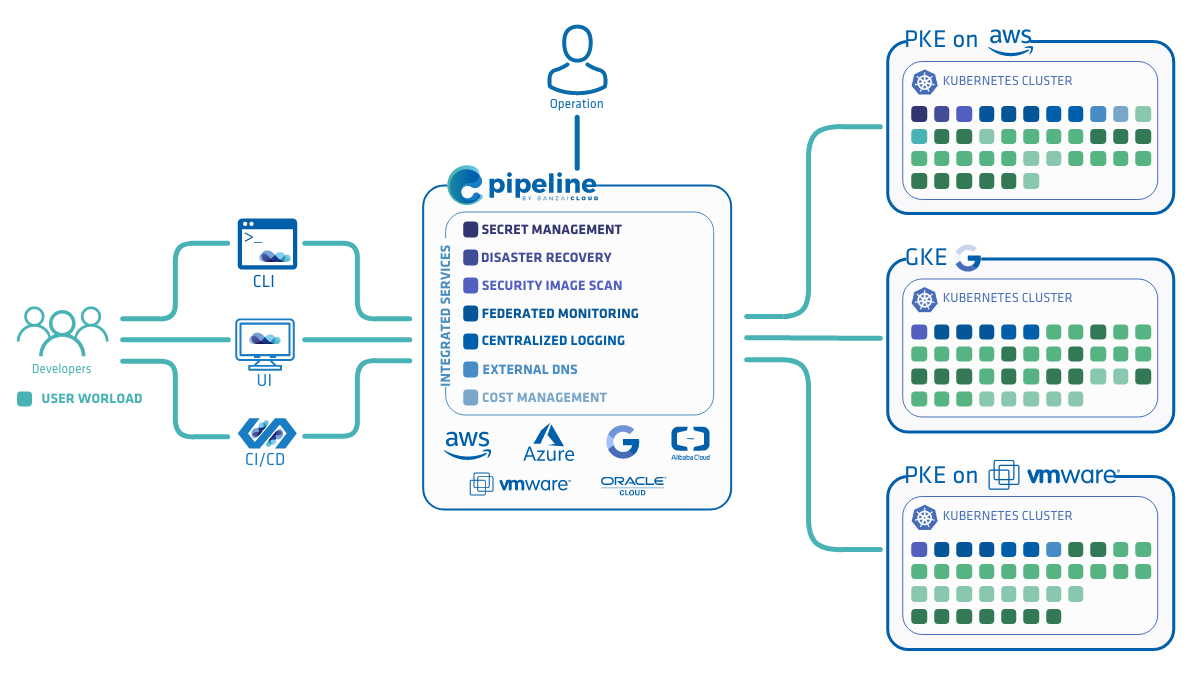
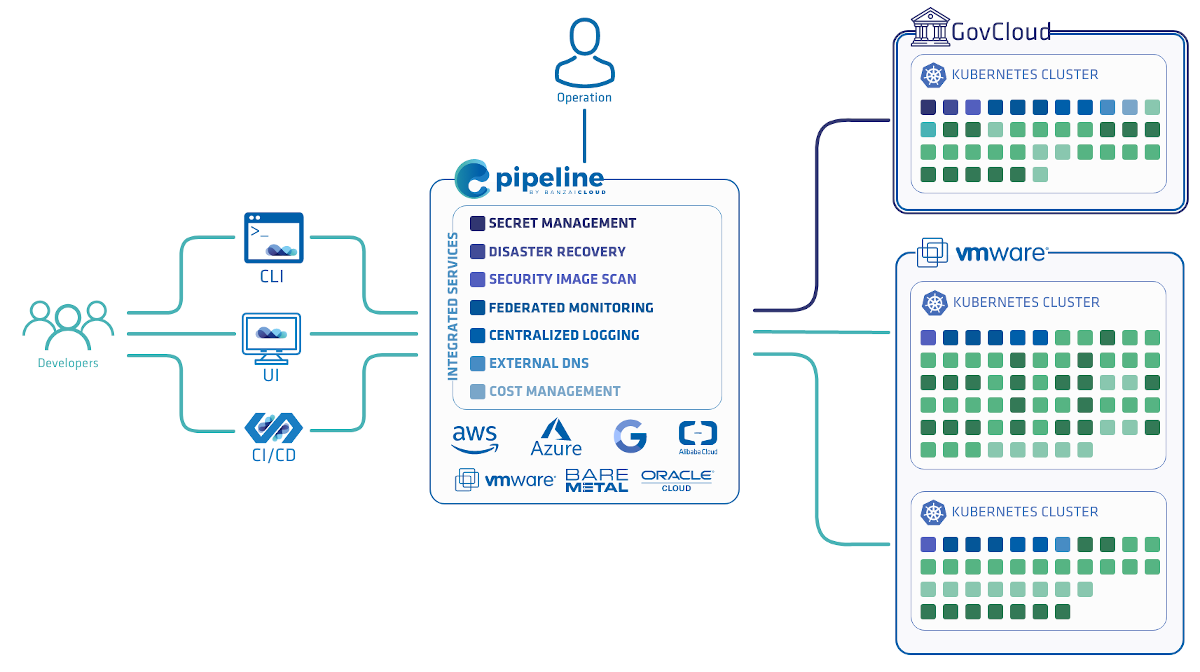
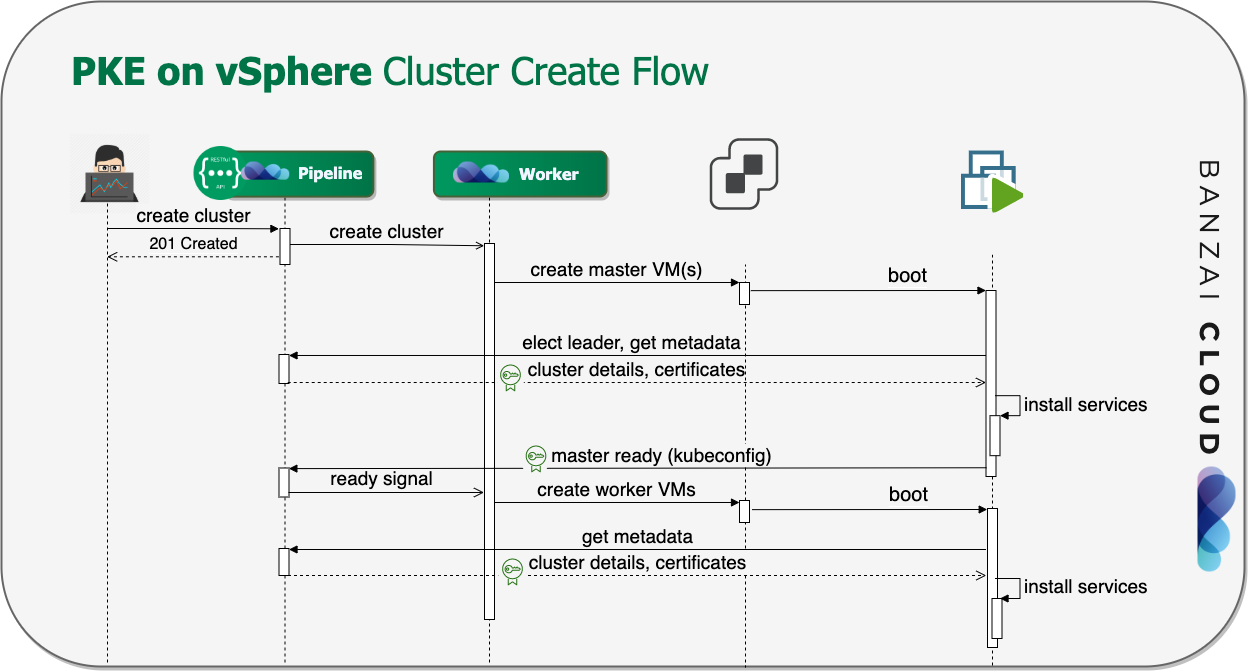
A few weeks ago we discussed the way that we integrated Kubernetes federation v2 into Pipeline, and took a deep dive into how it works. This is the next post in our federation multi cloud/cluster series, in which we’ll dig into some real world use cases involving one of Kubefed’s most interesting features: Replica Scheduling Preference.
A few weeks ago we discussed the way that we integrated Kubernetes federation v2 into Pipeline, and took a deep dive into how it works. This is the next post in our federation multi cloud/cluster series, in which we’ll dig into some real world use cases involving one of Kubefed’s most interesting features: Replica Scheduling Preference.
























